If you land to this post probably it’s because you have some interest on the topic (see all the requirements here) and we can now move to define more in details how this process should work:
- define how to structure the input/output focusing on who does what
- define how to configure the above in a way which will gave us an high level of scalability and reusability
- design a logging system in order to monitor and analyze which are the actions taken by the system helping the troubleshoting
1) Input and Ouput Definition
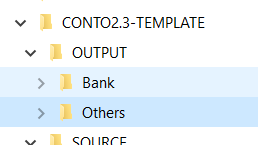
Once the information are extracted from the source they need to be exported to an OUTPUT folder also divided in two different folders which will contains all the original files in the same format and without any difference based on the owner, and this will simplify a lot the Exel job
The last step is on Excel itself which will load those files and will populate some spreadsheets in order to correctly display them in a proper Pivot table.
There is stil one part miss tough which is the Mapping. Who is mapping the information in the files and where this mapping is coming from? Unfortunately this is the most painful part, since my expectation is to manage the mapping in a totally separated Excel file where I can define whether a description is categorized in a way or another. This is the tricky part an the reason why Excel is not enough but we need PowerShell help. Basically, just right after the script run it will load all the mapping information and then it will reuse them to correctly map the expenses in a way easy to be managed by Excel.
2) How to configure the process
All what we said so far it just the base logic but in order to easely maintein and extend the process we need a configuration file which will tell where to find the files and the information within the files. This is key to avoid change code in case of any change in the sources.
3) How to log
Finally, in order to have a good level of details on what we the process did so far we need a way to log the actions for an easy troubleshooting
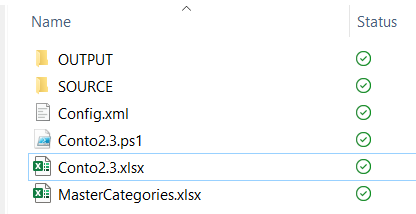
To resume:
- Config.xml: it’s the file containing the configuration
- Conto2.3.ps1: it’s the file where the ET (Extract and transform) logics will be performed
- Conto2.3.xlsx: it’s the Excel file which will manage the L (Load) and create the Pivot
- MasterCategories.xlsx: it’s the file used for the mapping during the ET phase
As said we would like to handle different file types coming from different sources: the bank account details, the credit card report and as well the owner: if me and my wife have different banks probably the source file will be different.
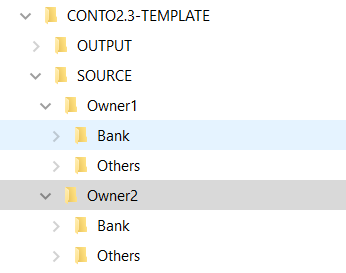
Theorically I would add asd much owner as I want, keeping a structure which may present the bank on first and then other sources. In thos folder I would also load the files as is without doing any manipulation
A PowerShell script which will be in the root folder will load those files and will normalize them. When I say normalize I mean to find a set of columns which are mandatory for the system:
- Data Operazione: the time of the spend
- Causale: brief indication of the reason
- Descrizione: a detailed info around the spend
- Ammontare: it is the the value of the spend
- Accredito: I noticed that in some cases we have found inbound placed in a different column from the outbound (Ammontare)
Once the information are extracted from the source they need to be exported to an OUTPUT folder also divided in two different folders which will contains all the original files in the same format and without any difference based on the owner, and this will simplify a lot the Exel job
The last step is on Excel itself which will load those files and will populate some spreadsheets in order to correctly display them in a proper Pivot table.
There is stil one part miss tough which is the Mapping. Who is mapping the information in the files and where this mapping is coming from? Unfortunately this is the most painful part, since my expectation is to manage the mapping in a totally separated Excel file where I can define whether a description is categorized in a way or another. This is the tricky part an the reason why Excel is not enough but we need PowerShell help. Basically, just right after the script run it will load all the mapping information and then it will reuse them to correctly map the expenses in a way easy to be managed by Excel.
2) How to configure the process
All what we said so far it just the base logic but in order to easely maintein and extend the process we need a configuration file which will tell where to find the files and the information within the files. This is key to avoid change code in case of any change in the sources.
3) How to log
Finally, in order to have a good level of details on what we the process did so far we need a way to log the actions for an easy troubleshooting
To resume:
- Config.xml: it’s the file containing the configuration
- Conto2.3.ps1: it’s the file where the ET (Extract and transform) logics will be performed
- Conto2.3.xlsx: it’s the Excel file which will manage the L (Load) and create the Pivot
- MasterCategories.xlsx: it’s the file used for the mapping during the ET phase