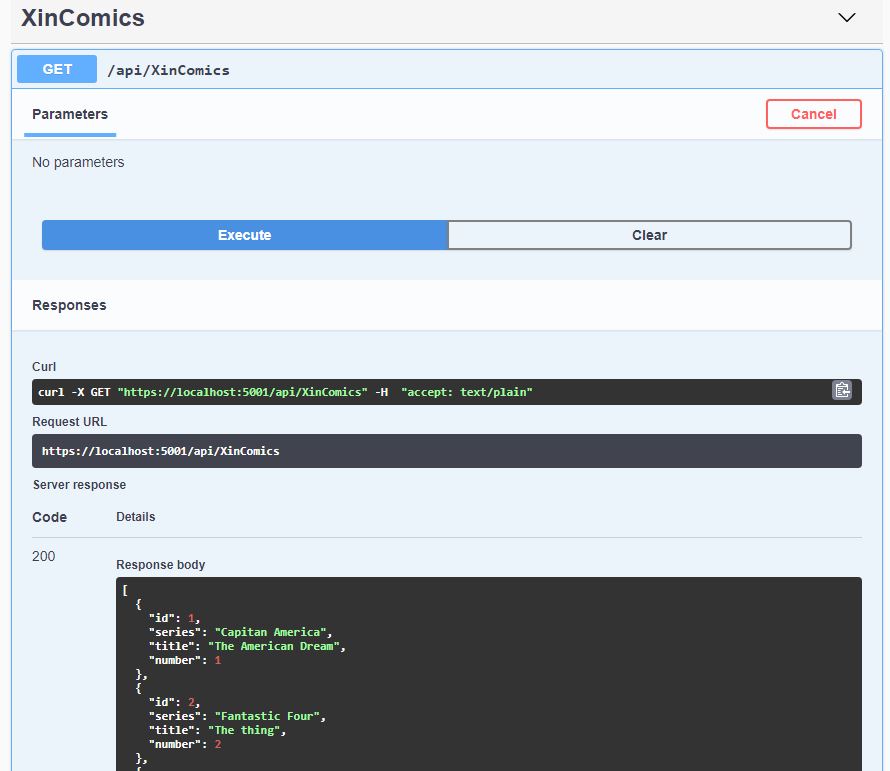
One of the most important reasons why WebAPIs have gained widespread popularity in recent years is the possibility of strongly decoupling the presentation part from that of the data layer/application layer. This strong decoupling, however, requires that radical changes to the WebAPI do not be to the detriment of those who consume them: if I change an API I should be sure that once changed everything that worked before continues to work in the same way otherwise I could potentially “break” some of the functionality of applications that consume these APIs. The best way to do this is to version the API, but before doing so you need to understand when it is necessary to create a new version of the API and when not. At this link [1] you can find a list of points on which I based my post. The main are the following:
- Rimove or rename an API or some of its parameters
- Singificant changes to the AI behaviour
- Changes to response contract
- Changes to error code
First we need to define the versions inside the Program.cs. In this case we also define version 1 as the default one.
builder.Services.AddApiVersioning(options =>
{
options.DefaultApiVersion = new ApiVersion(1);
options.ReportApiVersions = true;
options.AssumeDefaultVersionWhenUnspecified = true;
options.ApiVersionReader = ApiVersionReader.Combine(
new UrlSegmentApiVersionReader(),
new HeaderApiVersionReader("X-Api-Version"));
}).AddApiExplorer(options =>
{
options.GroupNameFormat = "'v'V";
options.SubstituteApiVersionInUrl = true;
});Then, it is necessary to decorate the controller with the supported versions and with the consequent dynamic path based on the version
[ApiVersion(1)]
[ApiVersion(2)]
[Route("api/v{v:apiVersion}/[controller]")]
public class InfoAPIController : ControllerBase
{At this point all the methods that have multiple versions with the same Http Get name but different C# name must be decorated
[MapToApiVersion(1)]
[HttpGet(Name = "GetInfo")] //, Authorize]
public string GetV1(string name)
{
...
[MapToApiVersion(2)]
[HttpGet(Name = "GetInfo")] //, Authorize]
public string GetV2(string name)
{Once this is done we should then be able to use different versions based on the path used. Actually, as explained well in the post below, the methods could be different but I opt for URL-based verisoning.
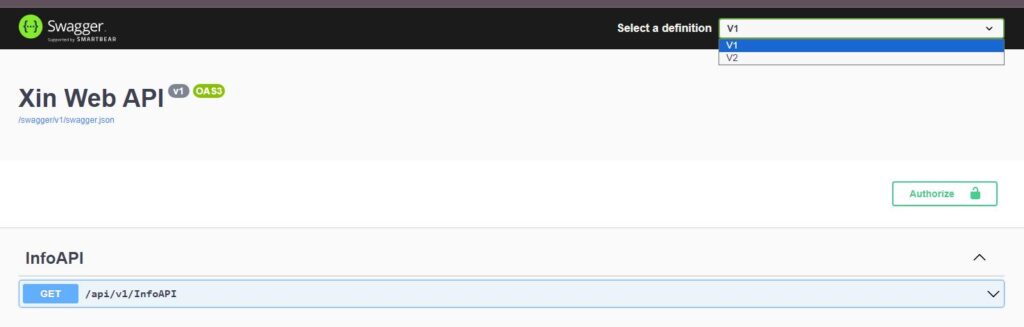
All very nice but all this is not enough to display two different versions in Swagger. To do this you need a couple of other lines of code that I discovered in another post [2]. The first is that the versions visible within the swagger configuration dropdown must be configured (in my case there are two):
builder.Services.AddSwaggerGen(options =>
{
options.AddSecurityDefinition("oauth2", new OpenApiSecurityScheme
{
In = ParameterLocation.Header,
Name = "authorization",
Type = SecuritySchemeType.ApiKey
});
options.OperationFilter<SecurityRequirementsOperationFilter>();
options.SwaggerDoc("v1", new OpenApiInfo { Title = "Xin Web API", Version = "v1"});
options.SwaggerDoc("v2", new OpenApiInfo { Title = "Xin Web API", Version = "v2" });
});
Finally, the version paths must be recorded in SwaggerUI, but instead of doing it one by one I recommend using the approach described here [3]
app.UseSwaggerUI(options =>
{
var descriptions = app.DescribeApiVersions();
// Build a swagger endpoint for each discovered API version
foreach (var description in descriptions)
{
var url = $"/swagger/{description.GroupName}/swagger.json";
var name = description.GroupName.ToUpperInvariant();
options.SwaggerEndpoint(url, name);
}
});Please note that the two steps above are fundamental if you want to correctly display both versions in the swagger drop down and switching between them. The two points above are fundamental.
[1] https://www.milanjovanovic.tech/blog/api-versioning-in-aspnetcore
[2] https://dev.to/sardarmudassaralikhan/swagger-implementation-in-aspnet-core-web-api-5a5a
[3] https://mohsen.es/api-versioning-and-swagger-in-asp-net-core-7-0-fe45f67d8419