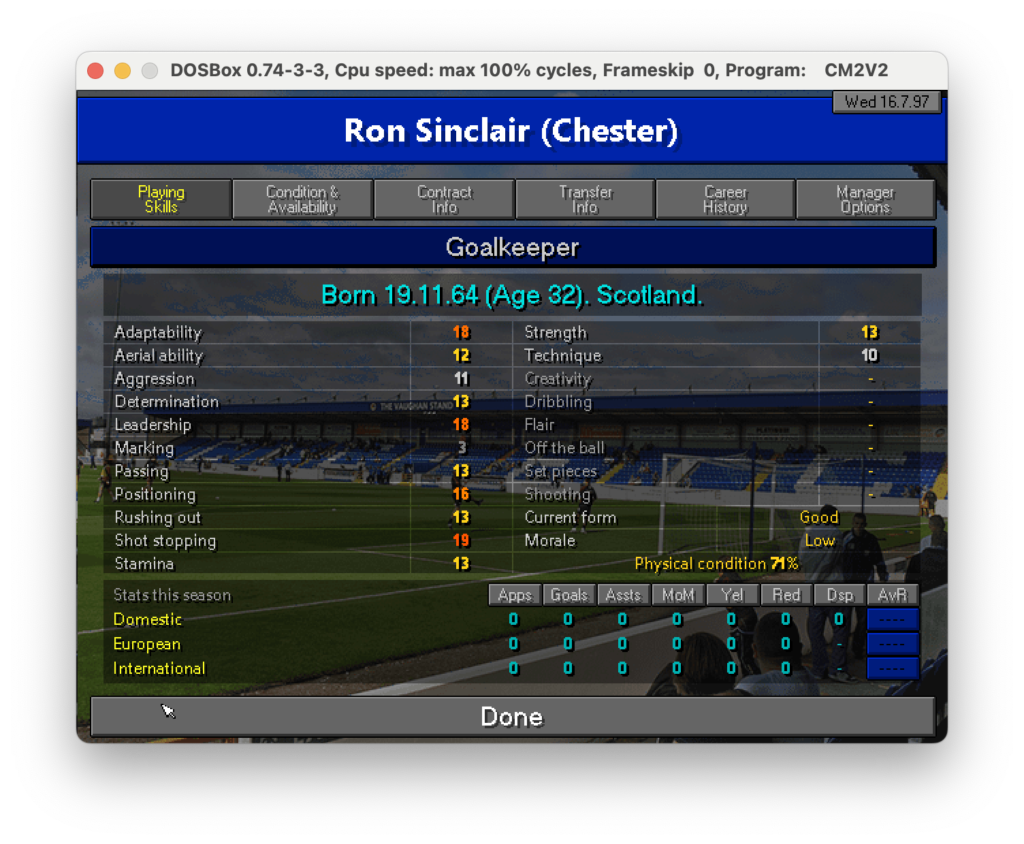
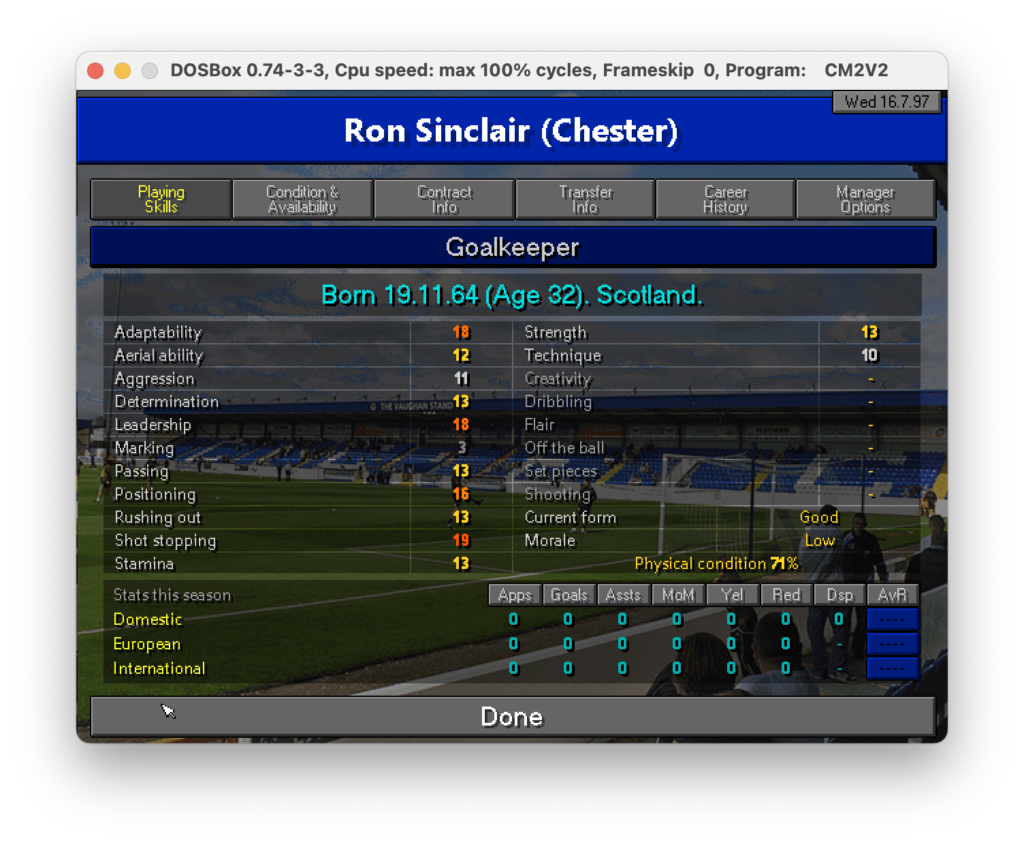
Nell’ultimo post di questa serie abbiamo scoperto come estrarre testo da specifiche parti di un’immagine. Ora, per proseguire nel progetto che ci siamo dati in origine (vedi qui) dobbiamo fare in modo che il dato letto sia correttamente salvato in un file CSV che poi importeremo in seguito. Quindi, ricapitolando: un csv che riporti nella prima colonna il la descrizione del campo come, nome, ruolo e skills e nella seconda colonna il valore di questi campi. Ad esempio nel caso seguente dovremmo partire dall’immagine:
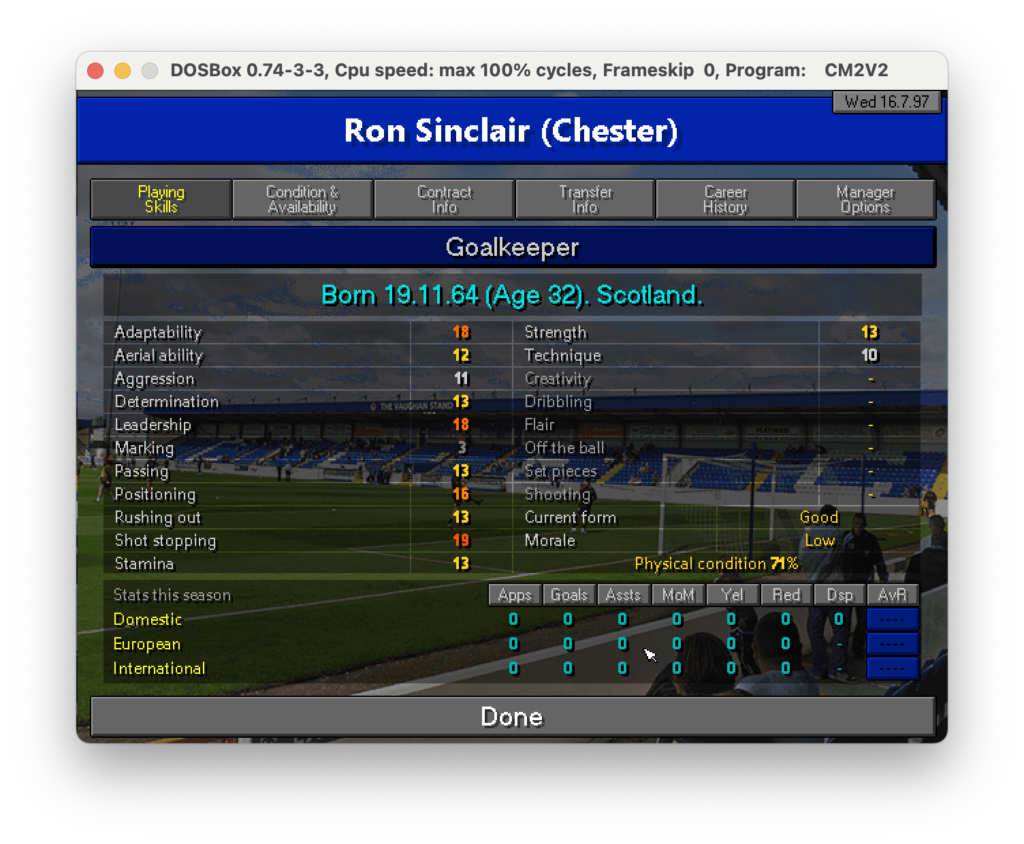
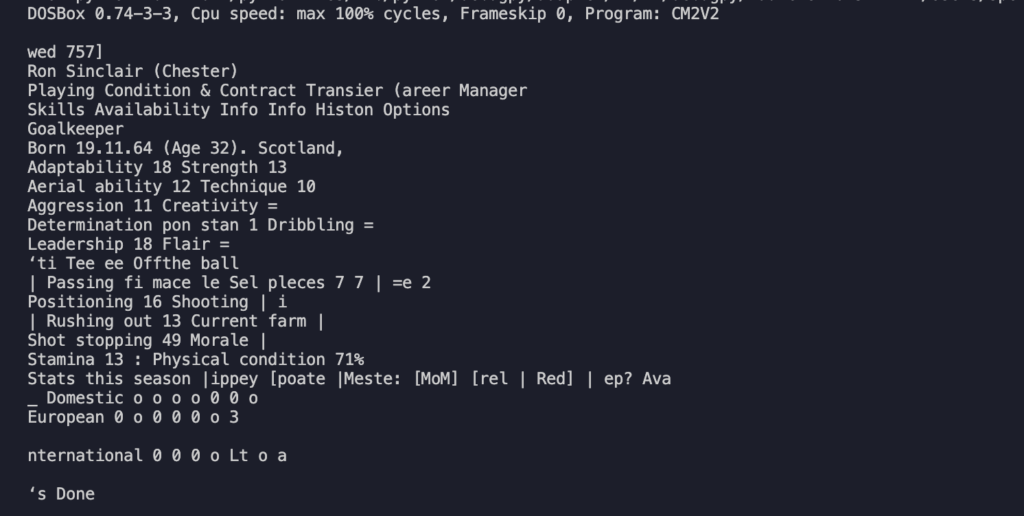
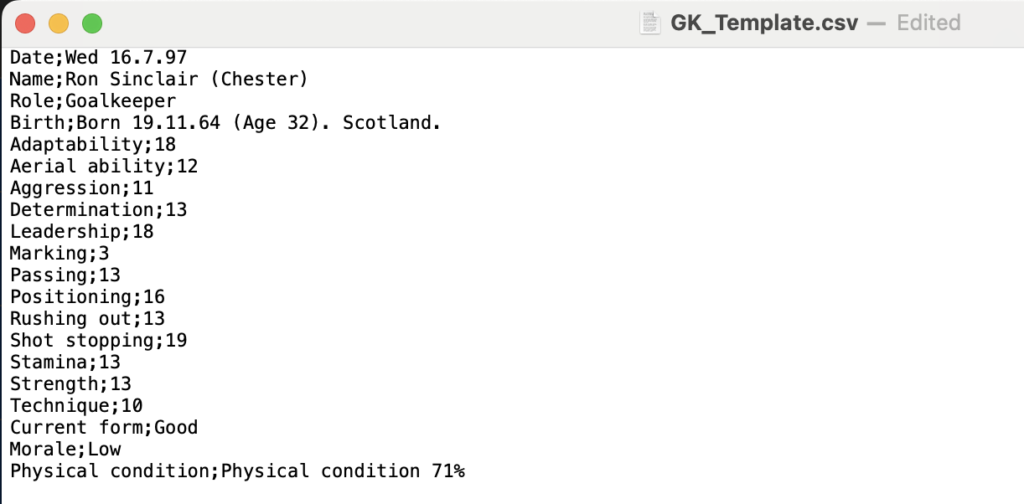
Per ottenere un csv che possa più o meno essere come il seguente:
Per falro anzitutto creo una funzione Python che mi data un’immagine e le dimensioni in cui è contenuta mi estragga il testo, così evito di dovre riscrivere tutte le volte il codice per estrarle, in più passo come parametro un booleano che, all’occorrenza, mi può anche far vedere l’immagine ritagliata prima di estrarre il testo.
# Function to extract data from a portion of screenshot
def extract_portion_for_csv(x,y,w,h,image,showimg):
roi = image[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
if showimg:
plt.imshow(gray_roi, cmap='gray')
plt.show()
export = pytesseract.image_to_string(gray_roi)
return exportOra che abbiamo una funzione che estrae il testo da specifiche parti dell’immagine si tratta solo di estrarre ognuna di esse definendo punto per punto dove recuperare il dato. Questa è la parte più noiosa in cui, testo per testo dobbiamo recuperare le coordinate. Per meglio organizzare le cose definisco 2 aree: quella in alto che contiene i dettagli anagrafici del profilo ed una sotto che contiene la parte di skills. Questo frammento estrae la parte anagrafica:
def extract_playerdetails_generic(img, showimg, matrix):
#Date
txt = extract_portion_for_csv(1225, 135, 148, 27, img, showimg)
new_row = ["Date", txt]
matrix.append(new_row)
#Name
txt = extract_portion_for_csv(110, 140, 1240, 100, img, showimg)
new_row = ["Name", txt]
matrix.append(new_row)
#Role
txt = extract_portion_for_csv(350, 326, 900, 70, img, showimg)
new_row = ["Role", txt]
matrix.append(new_row)
#Birth
txt = extract_portion_for_csv(350, 400, 900, 70, img, showimg)
new_row = ["Birth", txt]
matrix.append(new_row)E questo frammento invece estrae la parte di skills:
def extract_playerdetails_skills(img,showimg,matrix):
txt = ""
ycursor, i =474, 1
#Left Side Skills
while i<12:
#Skill Desc
#txt += extract_portion_for_csv(150, ycursor, 250, 30, img, showimg) + ","
txta = extract_portion_for_csv(150, ycursor, 250, 30, img, showimg)
#Skill Value
#txt += extract_portion_for_csv(650, ycursor, 50, 30, img, showimg) + "\n"
txtb = extract_portion_for_csv(650, ycursor, 50, 30, img, showimg)
new_row = [txta, txtb]
matrix.append(new_row)
i=i+1
ycursor += 34
#Right Side Skills
xoffset = 600
ycursor, i =474, 1
while i<9:
#Skill Desc
#txt += extract_portion_for_csv(150+xoffset, ycursor, 250, 30, img, showimg) + ","
txta = extract_portion_for_csv(150+xoffset, ycursor, 250, 30, img, showimg)
#Skill Value
#txt += extract_portion_for_csv(650+xoffset, ycursor, 50, 30, img, showimg) + "\n"
txtb = extract_portion_for_csv(650+xoffset, ycursor, 50, 30, img, showimg)
new_row = [txta, txtb]
matrix.append(new_row)
i=i+1
ycursor += 34
#Current form
#txt += "Current form," + extract_portion_for_csv(475+xoffset, 34*8 + 474, 250, 30, img, showimg) + "\n"
txt = extract_portion_for_csv(475+xoffset, 34*8 + 474, 250, 30, img, showimg)
new_row = ["Current form", txt]
matrix.append(new_row)
#Morale
#txt += "Morale," + extract_portion_for_csv(475+xoffset, 34*9 + 474, 250, 30, img, showimg) + "\n"
txt = extract_portion_for_csv(475+xoffset, 34*9 + 474, 250, 30, img, showimg)
new_row = ["Morale", txt]
matrix.append(new_row)
#Physical Condition
#¶txt += "Physical Condition," + extract_portion_for_csv(250+xoffset, 34*10 + 474, 400, 30, img, showimg) + "\n"
txt = extract_portion_for_csv(250+xoffset, 34*10 + 474, 400, 30, img, showimg)
new_row = ["Physical Condition", txt]
matrix.append(new_row)Ad una prima analisi possono sembrare complessi ma in realtà non lo sono: sono semplicemente abbastanza ripetitivi. Per ognuno dei testi che dobbiamo estrarre facciamo in modo di specificare le coordinate e mettiamo tutti i testi all’interno di una matrice così da utilizzarla poi nella scrittura del file csv tramite questo frammento:
def write_to_csv (csv_folder, csv_filename, matrixtowrite):
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerows(matrixtowrite)Come si può notare riempiamo una variabile matrix, una matrice che poi utilizzero per scrivere il file stesso. Il file generato contiene l’estrazione completa, confrontandola con la desiderata notiamo delle differenze:
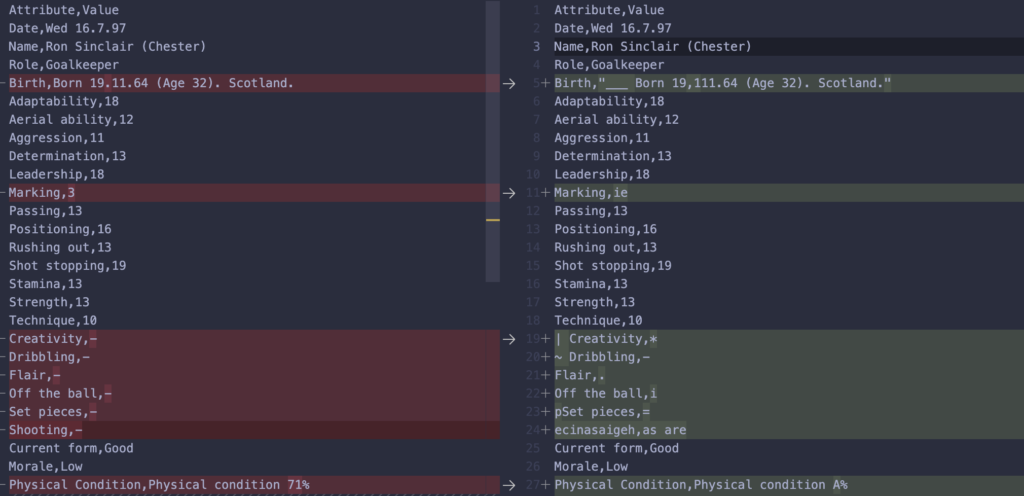
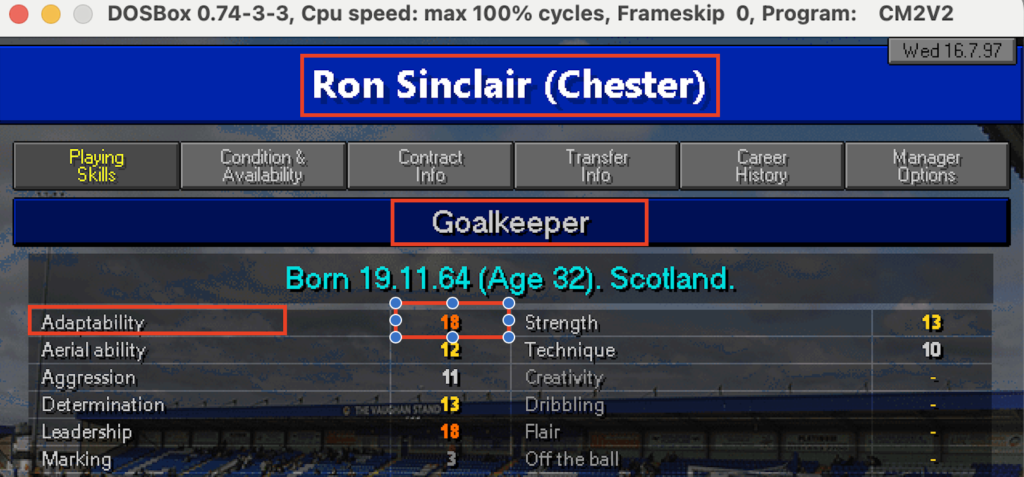
Come si può notare il risultato non è male ma lontano dall’essere perfetto: ci sono molti caratteri speciali che sporcano la lettura come “_”, “*”, “=”. Probabilmente le parti meno riconoscibili sono i trattini “-” e i numeri che hanno un colore del font minore meno pronunciato come quello in Marking 3. Il sistema sembra fare fatica a lavorare dove c’è un contrasto basso. Se guardiamo infatti la figura possiamo notare che tutte le parti che non sono state riconosciute sembrano essere meno evidenti delle altre.
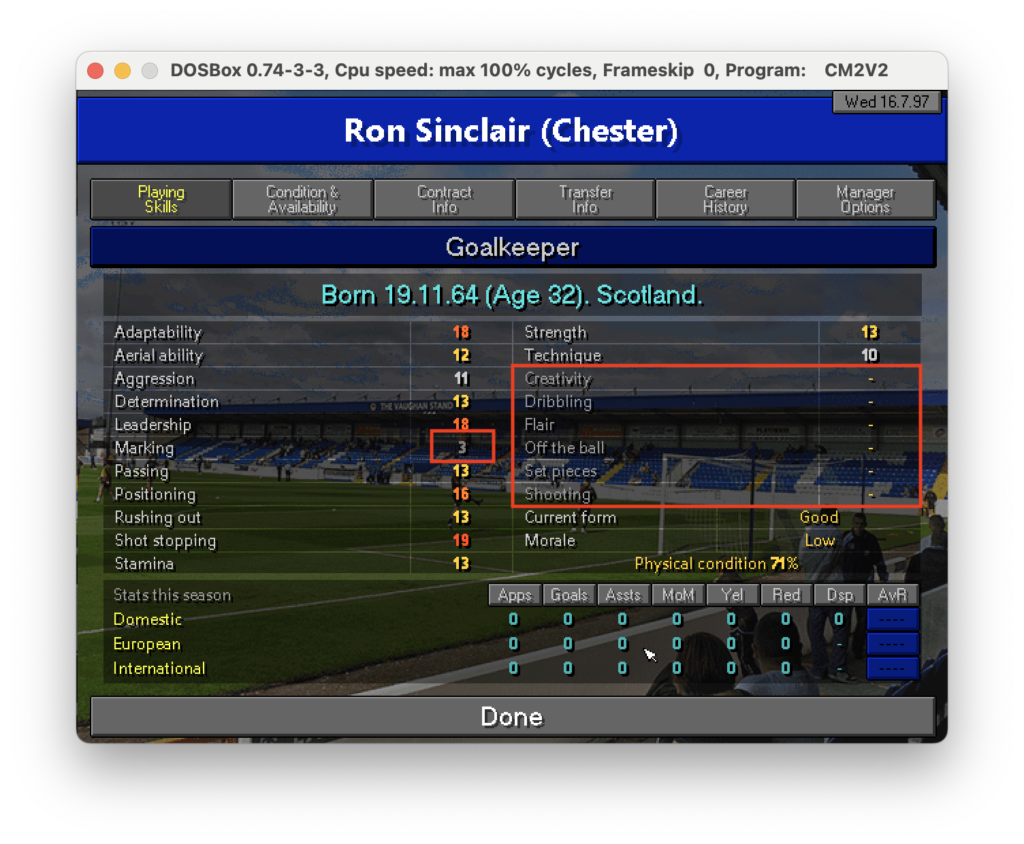
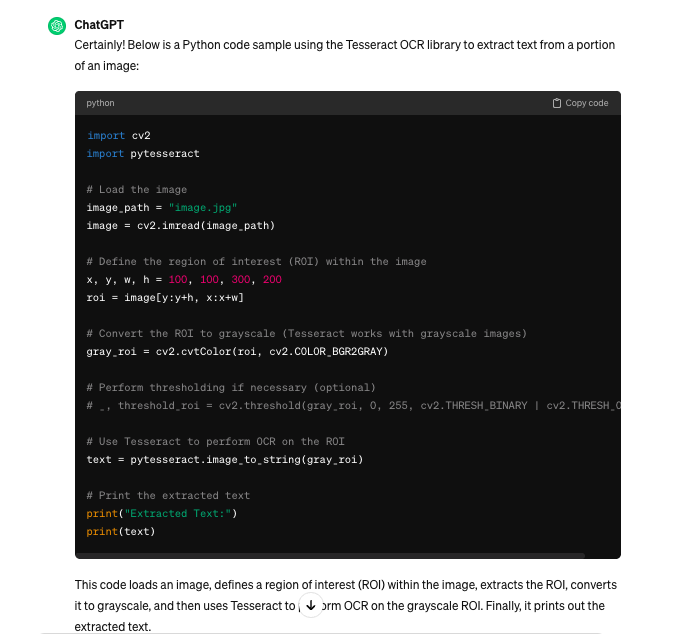
E’ chiaro che un file così non può essere importato per essere acquisito. L’ideale è capire come migliorare la qualità dell’estrazione, specie per quei caratteri che hanno un basso contrasto. Proviamo a fare una domanda specifica a ChatGPT:

La risposta purtroppo non preannuncia nulla di buono: sembra non sia così semplice . Nel prossimo post analizzeremo le proposte di ChatGPT e proveremo a capire se è possibile migliorare il risultato.