Nel precedente post al fine di provare ad acquisire e aggregare dati provenienti da schermate di un video gioco anni novanta abbiamo chiesto a ChatGPT di darci una mano nel compito essendo neofiti totali. La scorsa volta ci siamo fermati all’installazione di Python, ora passiamo a Tesseract.
Tesseract
Se proviamo a far girare il codice che ci ha fornito ChatGPT scopriamo che manca un prerequisito che è Tesseract. Ma cos’è esattamente?

Ecco la risposta sempre di ChatGPT

Bene, Tesseract è un OCR ed è utilizzato per estrarre testi dalle immagini: quello che mi serve. E’ Open-Source, supporta il riconoscimento in varie lingue ed è molto accurato se correttamente “allenato” (interessante). Può essere facilmente utilizzato attraverso API e nello sopecifico per sessere tuilizzato in Python necessita della libra “pytesseract”. Direi che è esattamente quello che mi serve. Per installare Tesseract basta un semplice comando con brew [1]
brew install tesseractInifine come suggerito da ChatGPT installo anche il wrapper per Python.
pip install pytesseractA questo punto possiamo cominciare a lavorare sul codice Python per capire come adattarlo e ricondurlo a quelle che sono le mie necessità.
Primo ciclo di codice
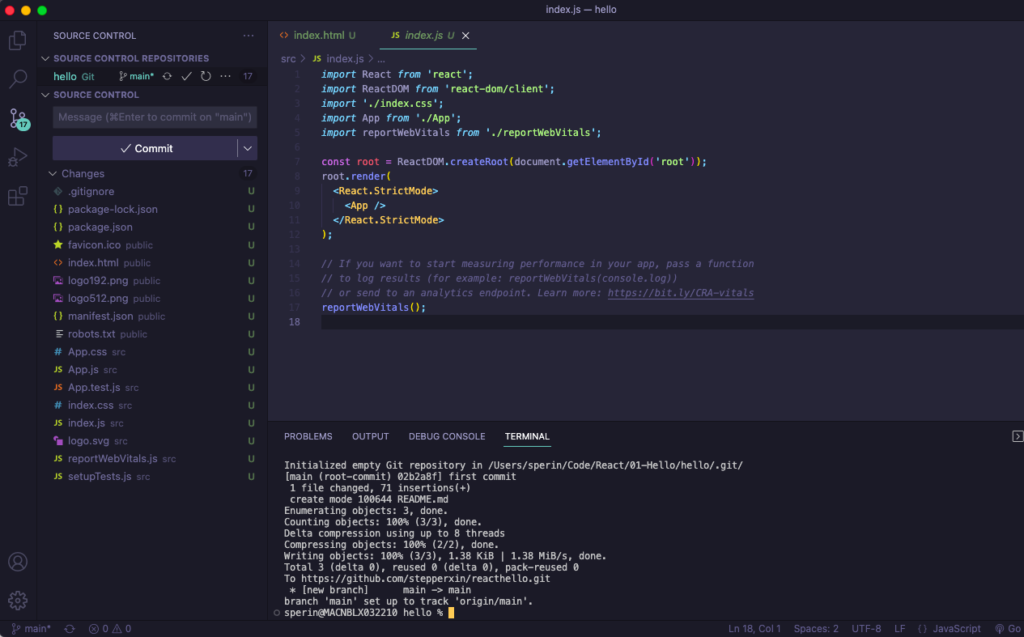
Apriamo Visual Studio Code e creiamo un file vuoto Test.py e copiamo il codice suggerito nel post precedente quindi lanciamo l’esecuzione dal menu Run > Start Debugging. Questo è il risultato:
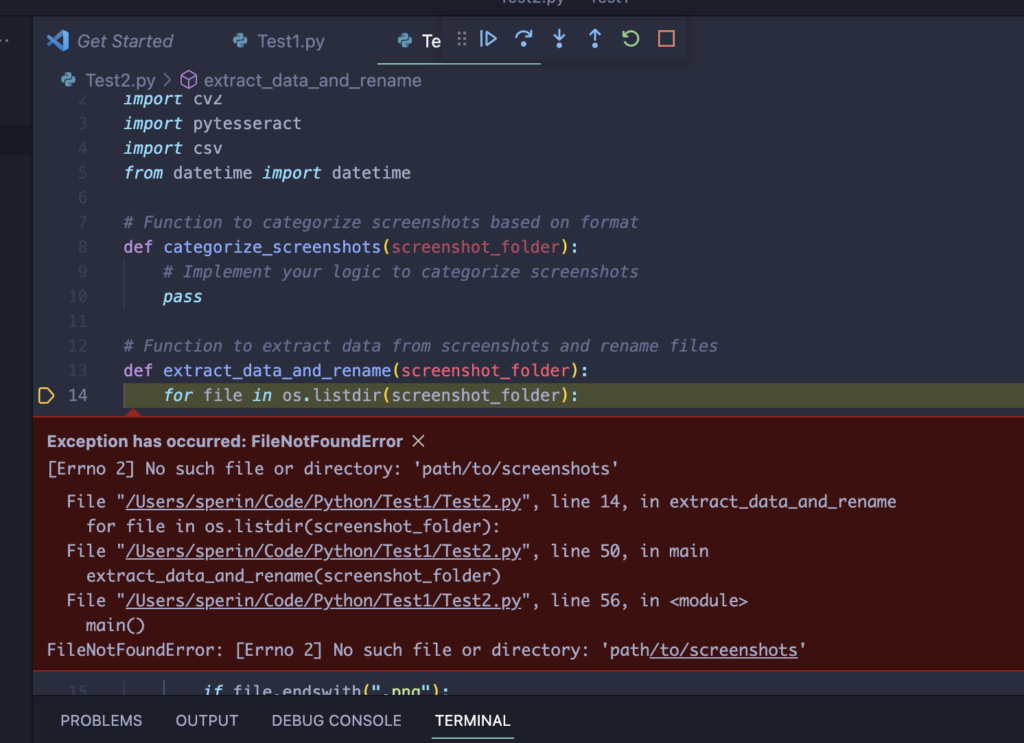
L’esecuzione va in errore e la modalità debug di Visual Studio Code ci aiuta evidenziando dove sta il problema: certo devo fornire un path corretto dove prelevare gli screenshots. Al netto di questo errore comunque il setup sembra corretto possiamo quindi dedicarci alla parte più divertene: vale a dire scrivere il codice. Anzitutto faccio un po’ di pulizia: rimuovo la parte che fa la categorizzazione perchè al momento non so ancora come poterla implementare e lo stesso faccio con la funzione che scrive il csv. Infine fornisco il path dove ho già preparato alcuni screenshots da cui estrarre il testo che mi serve. Il main dopo questo restyling è molto minimale:
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = ""/Users/xxxx/ScreenCapture""
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)Infine mi dedico alla funzione principale extract_data_and_rename che chiaramente itera i files nella cartella e tramite pytesseract estrae il testo dell’immagine. Al momento però mi limito a fare un print del dato estratto:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
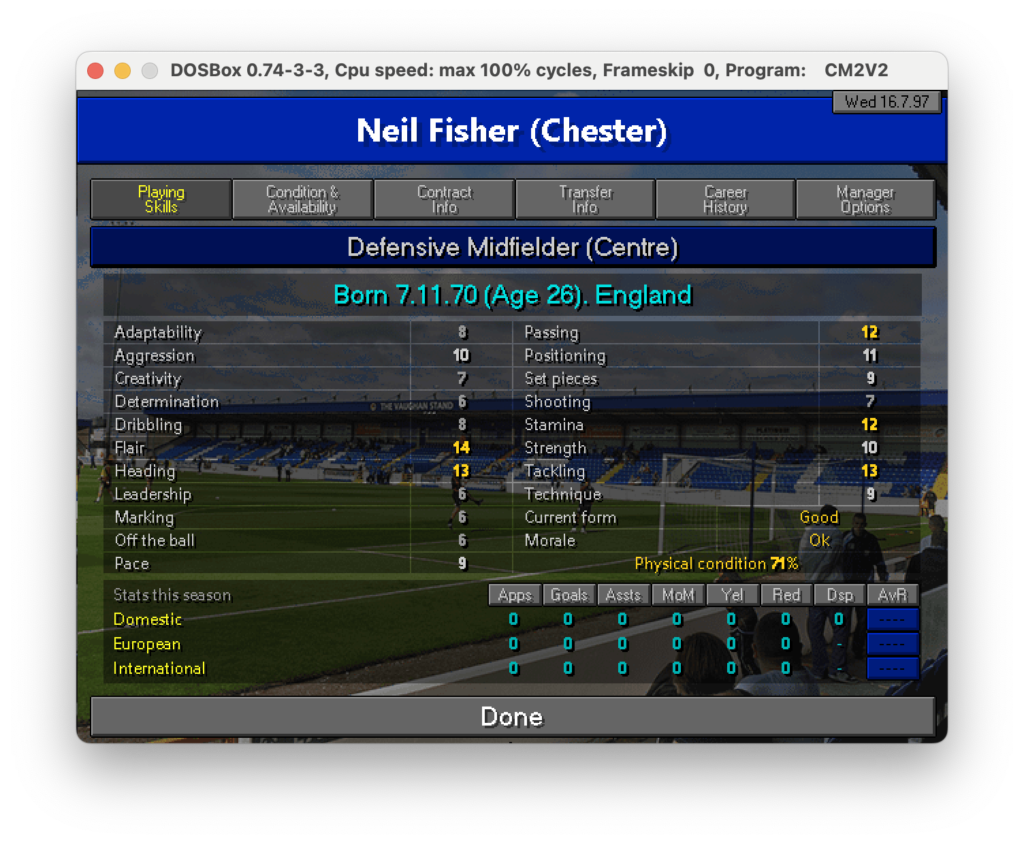
print(extracted_data)Ok ci siamo se lo lanciamo teoricamente dovrebbe iterare tutti i files png presenti nella cartella e scrivere il contenuto estratto da ognuno di essi a schermo. Per questa prima prova uso una sola immagine:
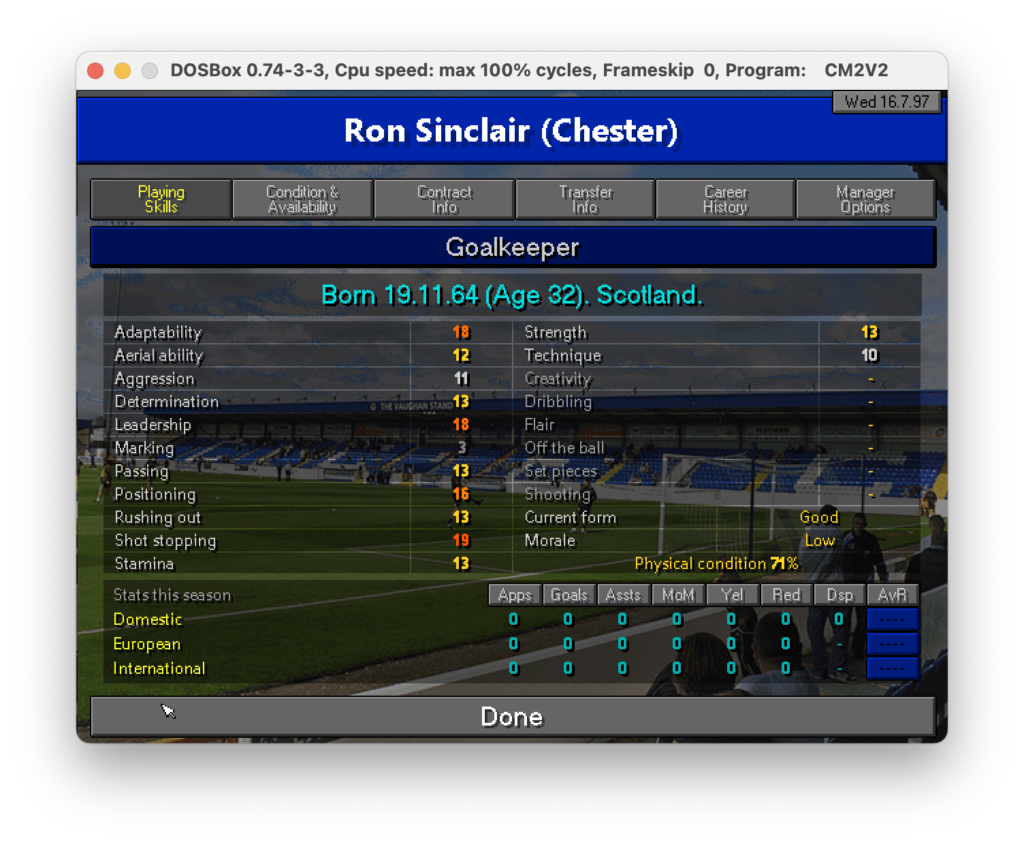
e questo è ciò che il sistema è stato in grado di interpretare:
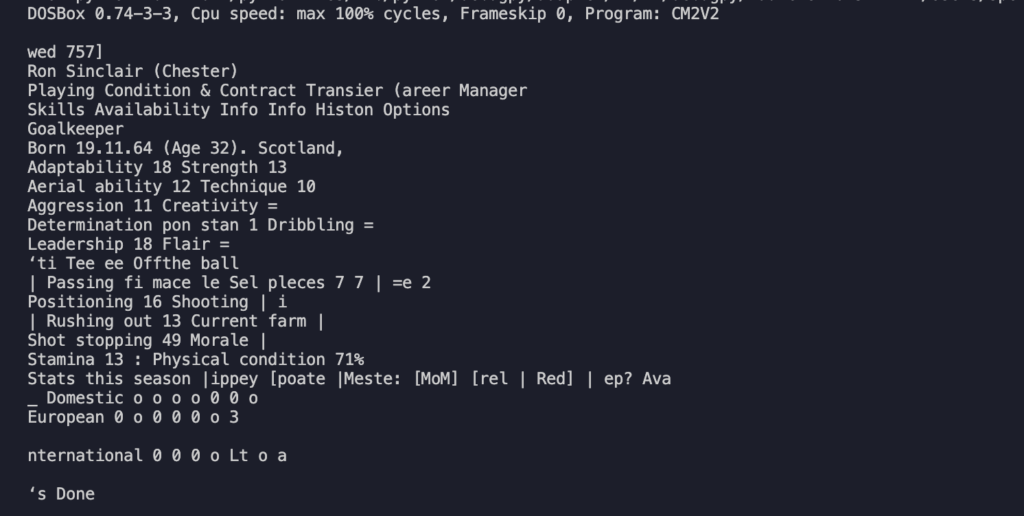
Beh, diciamo che come primo test è già qualcosa però è evidente che alcuni testi sono stati correttamente interpretati mentre altri vanno rivisti. C’è parecchio da lavorare!