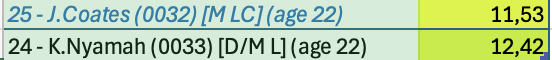Dopo una prima stagione abbastanza rivedibile, quella 1998/99 potrà essere ricordata come la stagione della riscossa. La squadra dopo essere sempre stata nelle zone alte della classifica conquisterà infatti la promozione in Second Division senza nemmeno passare dai Play-Offs.
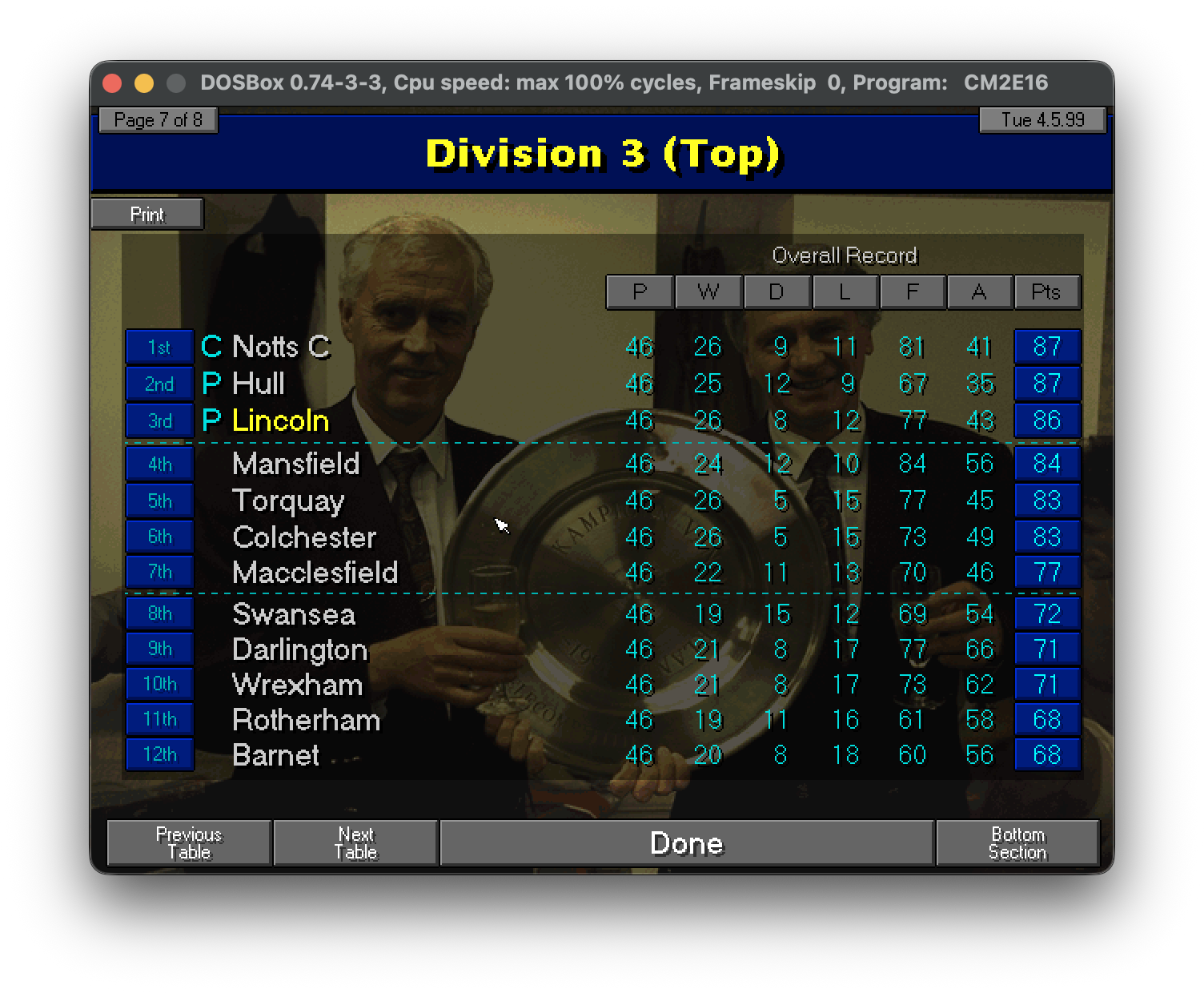
La classifica finale della stagione 98/99
La Stagione
Il campionato comincia a rilento: 2 punti nelle prime tre partite, sembra di rivivere la falsa riga dell’anno precedente in cui per larga parte abbiamo annaspato alla ricerca di una continuità mai trovata. Dalla quarta partita la squadra ingrana invece la quinta (scusate il gioco di parole) e da lì macina risultati su risultati al punto da risalire stabilmente in zona play-offs.
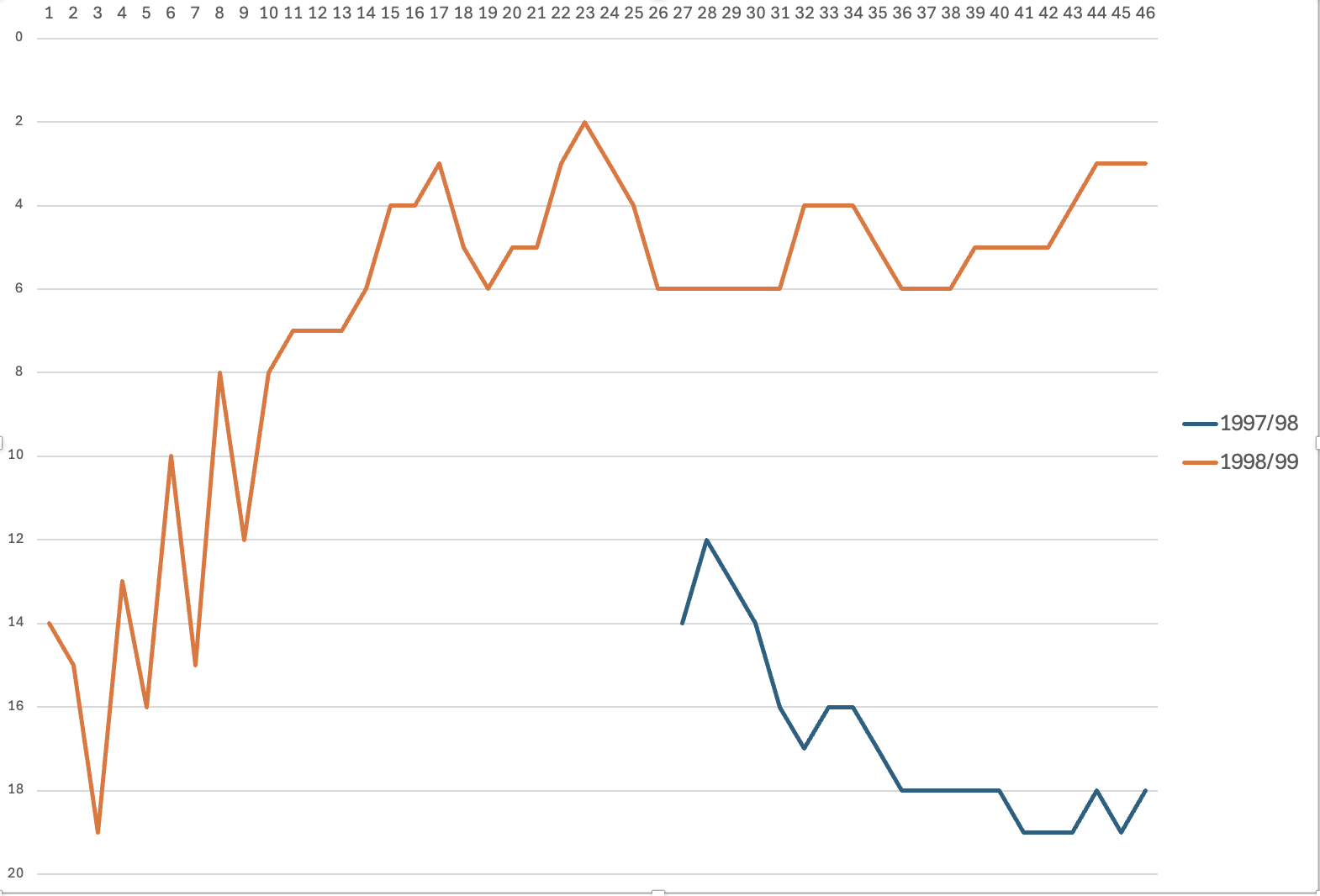
Posizione in classifica nel 98/99
Come si vede dal grafico della posizione in classifica il crescendo è stato continuo. Addirittura per una giornata siamo addirittura stati secondi e cmq dalla 10ma in poi siamo sempre stati in zona playoff.
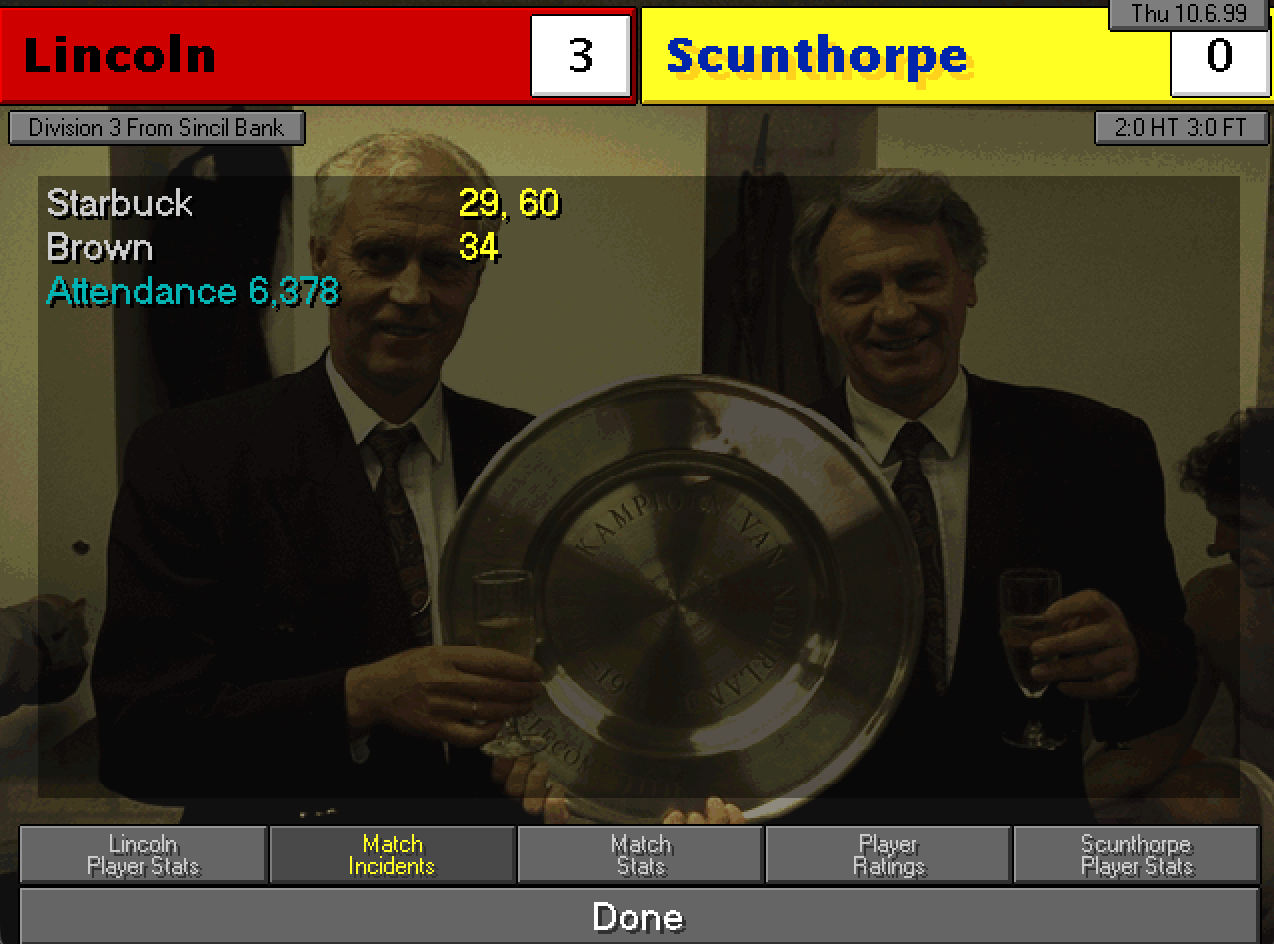
La Partita
Partita simbolo della stagione è quella dell’ultima di campionato contro lo Scunthorpe: basta un pareggio per terminare nelle prime tre che accedono direttamente alla Second Division. La partita è carica di tensione e nei primi minuti sembriamo essere un po’ in difficoltà per via del peso della gara. Poi però alla lunga viene fuori la differenza tra le due squadre (lo Scunthorpe è in fondo alla classifica) e trionfiamo 3-0.
46ma di campionato che sancisce la promozione in Second Division
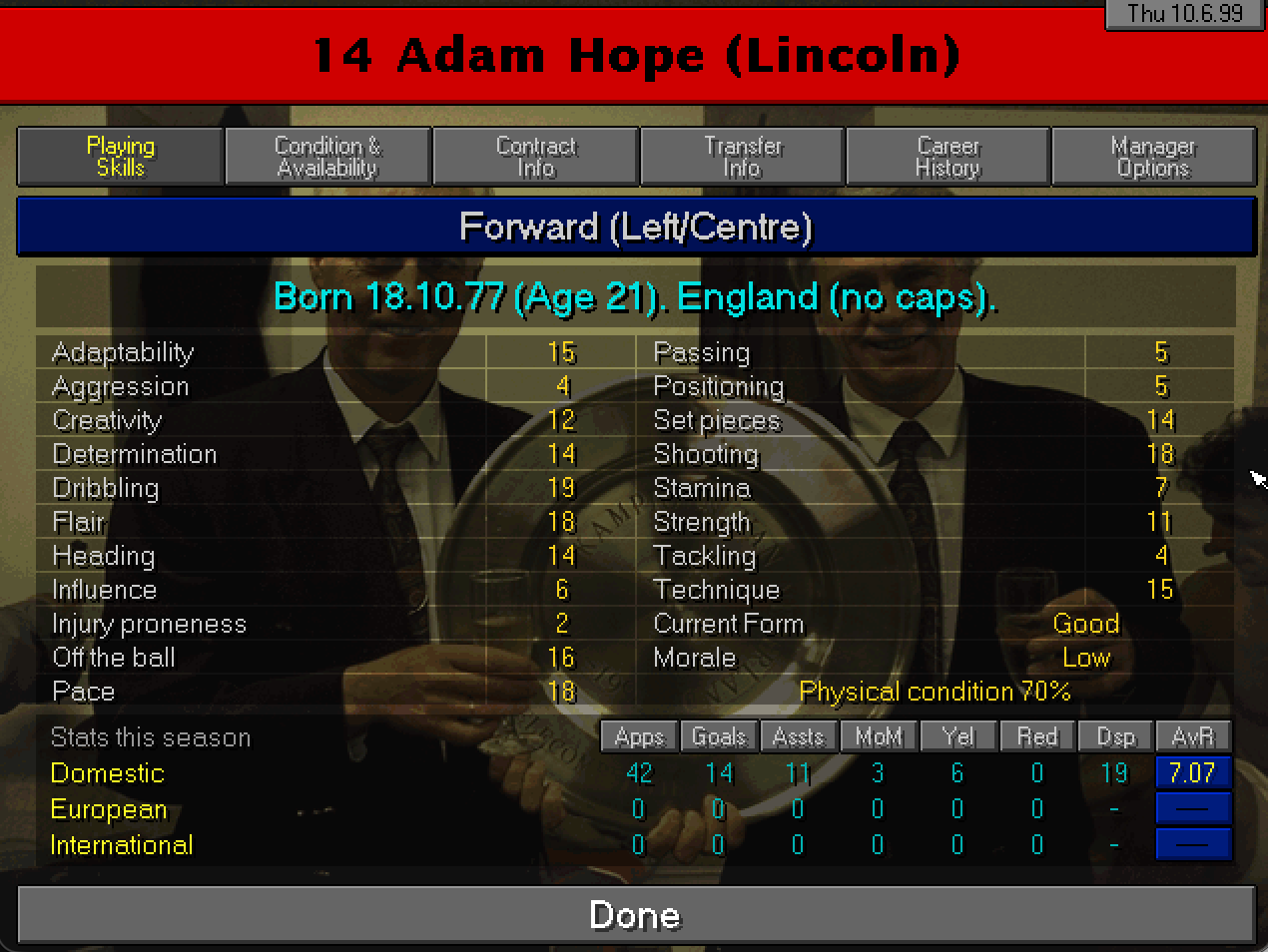
Il Giocatore
Dovendo fare un nome per la stagione decisamente emerge il nome di Hope un attaccante pescato tra i giocatori senza contratto è diventato quasi subito attaccante titolare: bravo a fare gol e altrettanto bravo a far segnare. Al termine della stagione avrà un valore stimato di 2M, non male per uno preso a zero vero?
Adam Hope
Le Finanze
Anche quest’anno le finanze sono state al centro di tutte le operazioni: in uscita confezionamo 3 operazioni di cui una che porta 1.1M nelle casse con la cessione del portiere Aldus, un plusvalenza notevole dato che anche lui era un parametro 0. Complessivamente quindi la situazione finanziaria è buona. Da notare che anche le entrate relative ai biglietti venduti sono raddoppiate, in linea con quelle che sono state le presenze allo stadio.
Una stagione interlocutoria per ri-prendere le misure con il gioco e fare esperienza
Il Lincoln City è una piccola realtà di Terza Divisione inglese. La società ha un budget molto risicato (appena 150K£ di disponibilità per fare mercato) e un roster malamente assortito, con intere zone del campo non coperte: non ci sono centrocampisti centrali di ruolo, ed altre invece con molti doppioni che rendono complicato riuscire a schierare una formazione con diversi giocatori fuori ruolo. Purtroppo fare mercato per migliorare la rosa non è facile con i pochi soldi che hai e se in più consideri che sei una squadra di modeste ambizioni: in pratica non ci vuole venire nessuno…
La Stagione
Malgrado le premesse, la stagione comincia molto bene: delle prime 5 giornate di campionato ne vinciamo ben 4, riuscendo anche, per qualche giorno ad essere primi in classifica grazie anche al fatto che non tutte le squadre siano a pieno numero di partite. Tra qualche alto e basso si arriva alla 12ma giornata in cui abbiamo collezionato 7V, 2P, 3S ed una posizione da pieno play-off, niente male non è vero? Beh, da lì, per vincere un’altra gara si dovrà attendere quasi 2 mesi… La squadra tra la fine di Settembre e Novembre si è come bloccata, i giocatori che prima sembravano delle certezze, spariti oppure deboli copie degli originali, insomma un bel dilemma. Da quel momento in poi è cominciata una picchiata in classifica che ha toccato il fondo solo al 19 posto. Unica nota positiva è che delle ultime 4 ne vinciamo 5. Ciò che mi porto a casa da questa stagione è che la squadra quando ha giocato i moduli base ha tratto quasi sempre migliori risultati di moduli custom improvvisati sui giocatori. Chiudiamo la stagione al 18mo posto, risultato non eccelso per quanto la dirigenza si sia mostrata tutto sommato contenta.
La Rosa
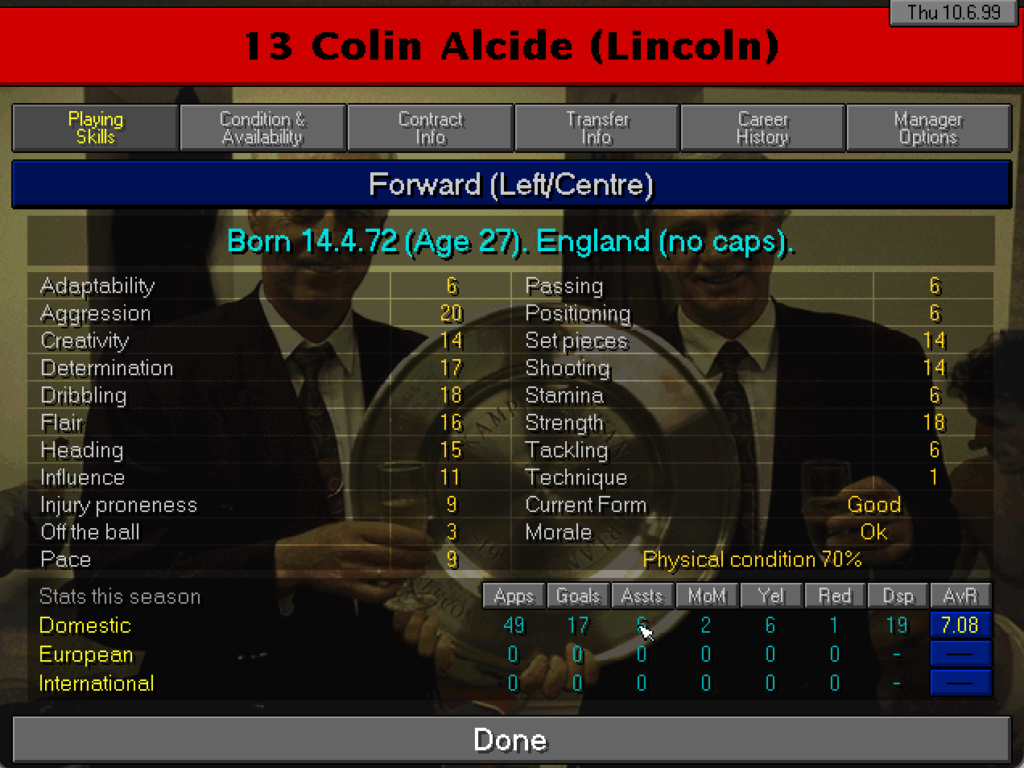
Nel contesto di una stagione complicata mi sento di nominare un paio di giocatori come tra quelli che hanno fatto sentire maggiormente la loro presenza. Il primo Alcide è un attaccante molto tecnico che ha giocato spesso nel 4-4-2 come centrocampista centrale con ottimi risultati sotto porta. L’altro Aldus è un portiere giovanissimo recuperato tra i giocatori senza contratto. Molto giovane, si è guadagnato quasi subito il posto da titolare ed entro la fine della stagione ha raggiunto un valore di mercato di 1M.
Colin Alcide
Le Finanze
Dal punto di vista economico la stagione è stata un vero supplizio: a Luglio c’era una disponibiltà di 150K che però si sono consumati rapidamente, viste le scarse entrate e soprattutto gli stipendi da pagare. Questo ha comportato che durante la stagione abbia dovuto rinunciare a parecchi giocatori per riuscire a coprire le spese.
Dopo qualche tempo dall’esperienza con lo Scunthorpe finita male, così come il PC su cui ci stavo giocando, nei ritagli di tempo ho cominciato una nuova stagione con un’altra squadra di 3rd Division inglese il Lincoln City. Questa volta ho deciso di riportare in un excel una serie di informazioni che possano venire utili durante il gioco anche per solo temi statistici. Di volta in volta esporrò alcuni di questi fogli excel per spiegare meglio a cosa servono e perchè li utilizzo.
La Squadra
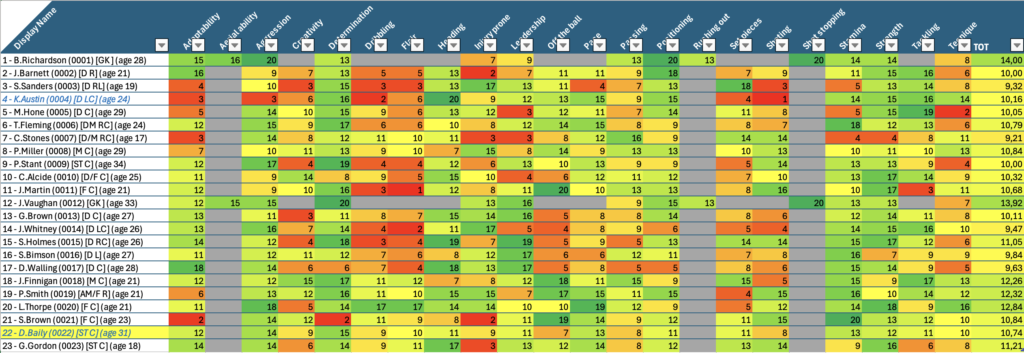
Nel foglio “PL Skills” ho riportato per tutti i giocatori le informazioni princiali quali ruolo, età, nazionalità e skills.
PL Skills
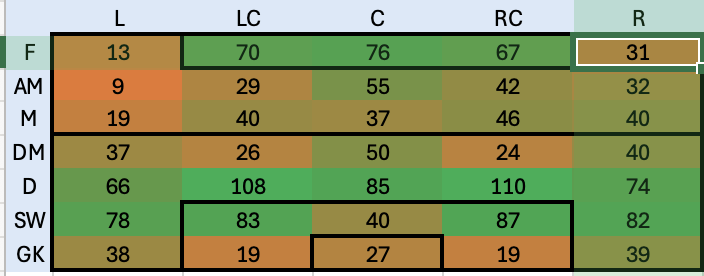
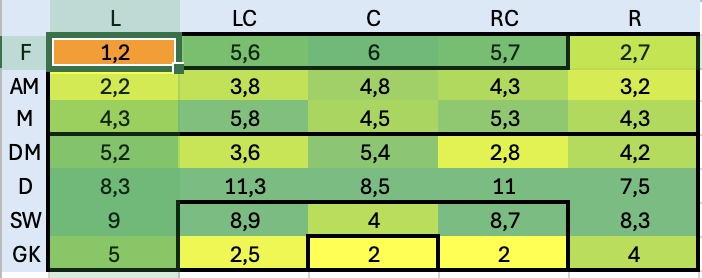
Questa tabella è usata come tabella principale su cui fare lookup per ogni giocatore in tutte le tabelle del foglio excel. In questo modo, anche con l’aiuto del colore (basso -> rosso, alto -> verde) dà già un’idea di massima di come siano distributite le skills ei giocatori. Sfruttando la potenza di PowerQuery mi sono costruito poi una roadmap che in base alle posizioni in campo va a distribuire le skills per dare un’idea di quanto siano coperte le varie parti del campo. il risultato è il seguente:
HitMap Player skills – Punti di forza e debolezza
E’ evidente com la parte di granlunga più debole sia la fascia sinistra ed anche la linea mediana non sembra avere un grosso ricambio. La parte centra dell’attacco e della difesa invece sembrano molto più coperte, probabilmente troppo. Decido quindi di buttarmi alla ricerca di esterni di sinistra che possano coprire meglio quella parte di campo.
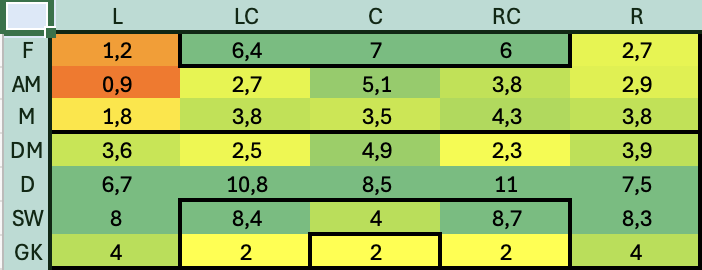
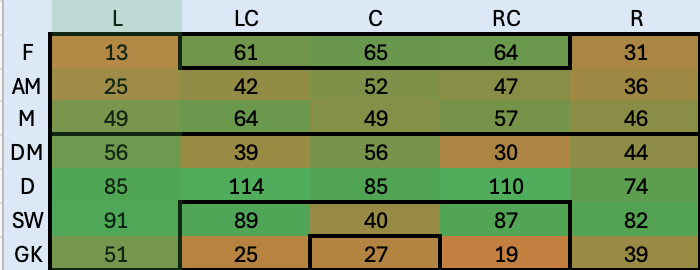
Similmente creo una Hitmap che identifichi la copertura del ruolo in modo da capire anche quelli che sono i ruoli meno coperti, non solo quelli più deboli
Hitmap Player Role Copertura
In questo caso l’indicazione è convergente con quella precedente: la fascia sinistra dalla meta campo in su è fortemente scoperta ed è certamente da rinforzare. Diciamo che da questa analisi ci portiamo a casa le seguenti informazioni:
Nei ruoli d’attacco abbiamo una grande abbondanza: in media abbiamo 6 contendenti per 2 posti (assumo di non giocare con 3 attaccanti)
La fascia sinistra richiede un bel boost
Nei ruoli di difesa, in particolare quelli centrali c’è una grande abbondanza con 10 contendenti per, probabilmente, 2 massimo 3 ruoli.
Precampionato e calcio mercato
Partendo dalle considerazioni di cui sopra organizzo 3 amichevoli precampionato per cominciare a vedere un po’ la squadra e capire con che modulo giocare ma soprattutto quali giocatori preferire.
Precampionato
La prima gara è con una squadra del nostro campionato in trasferta. Per la formazione mi faccio guidare da come è composta la rosa e schiero un 3-5-2 che però non mi convince, perdiamo 2-1 senza molte luci. Al termine di questa gara mi viene fatta un’offerta molto interessante per Baily attaccante 31enne in scadenza di contratto a fine anno. Accetto: in attacco siamo molto coperti ed un modo anche per fare cassa. Per la seconda gara, sempre contro una squadra della nostra division, schiero un classico 4-4-2 adattando un centrale sulla sinistra non avendo giocatori di ruolo: va alla grande vinciamo 4-1 dominando sostanzialmente la gara. A questo punto bollo il 4-4-2 come modulo migliore o cmq più affidabile al momento. In questa settimana riesco a mettere anche a segno un paio di acquisti per la fascia sinistra:
Due nuovi acquisiti
Dopo questi cambi nell’organico le nuove hitmap sono le seguenti:
Nell’ultima gara del precampionato affrontiamo in casa un squadra di Second Division, finisce 0-0 non molte occasioni. Nyamah ha giocato solo il primo tempo senza incidere particolarmente.
Non resta dunque che partire con la stagione che comincia con un trasferta per un mese d’agosto massacrante in cui si giocherà ogni 3-4 gg.
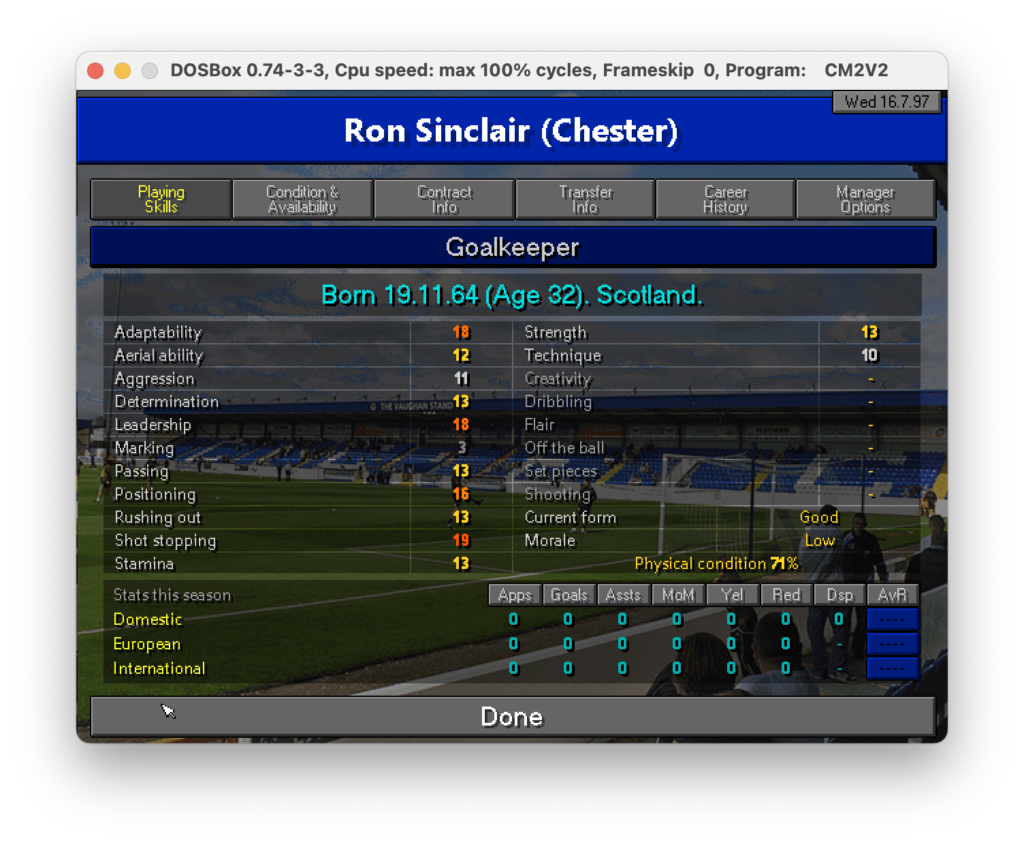
Nell’ultimo post di questa serie abbiamo scoperto come estrarre testo da specifiche parti di un’immagine. Ora, per proseguire nel progetto che ci siamo dati in origine (vedi qui) dobbiamo fare in modo che il dato letto sia correttamente salvato in un file CSV che poi importeremo in seguito. Quindi, ricapitolando: un csv che riporti nella prima colonna il la descrizione del campo come, nome, ruolo e skills e nella seconda colonna il valore di questi campi. Ad esempio nel caso seguente dovremmo partire dall’immagine:
Scheda calciatore
Per ottenere un csv che possa più o meno essere come il seguente:
Esportazione desiderata
Per falro anzitutto creo una funzione Python che mi data un’immagine e le dimensioni in cui è contenuta mi estragga il testo, così evito di dovre riscrivere tutte le volte il codice per estrarle, in più passo come parametro un booleano che, all’occorrenza, mi può anche far vedere l’immagine ritagliata prima di estrarre il testo.
# Function to extract data from a portion of screenshot
def extract_portion_for_csv(x,y,w,h,image,showimg):
roi = image[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
if showimg:
plt.imshow(gray_roi, cmap='gray')
plt.show()
export = pytesseract.image_to_string(gray_roi)
return export
Ora che abbiamo una funzione che estrae il testo da specifiche parti dell’immagine si tratta solo di estrarre ognuna di esse definendo punto per punto dove recuperare il dato. Questa è la parte più noiosa in cui, testo per testo dobbiamo recuperare le coordinate. Per meglio organizzare le cose definisco 2 aree: quella in alto che contiene i dettagli anagrafici del profilo ed una sotto che contiene la parte di skills. Questo frammento estrae la parte anagrafica:
Ad una prima analisi possono sembrare complessi ma in realtà non lo sono: sono semplicemente abbastanza ripetitivi. Per ognuno dei testi che dobbiamo estrarre facciamo in modo di specificare le coordinate e mettiamo tutti i testi all’interno di una matrice così da utilizzarla poi nella scrittura del file csv tramite questo frammento:
def write_to_csv (csv_folder, csv_filename, matrixtowrite):
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerows(matrixtowrite)
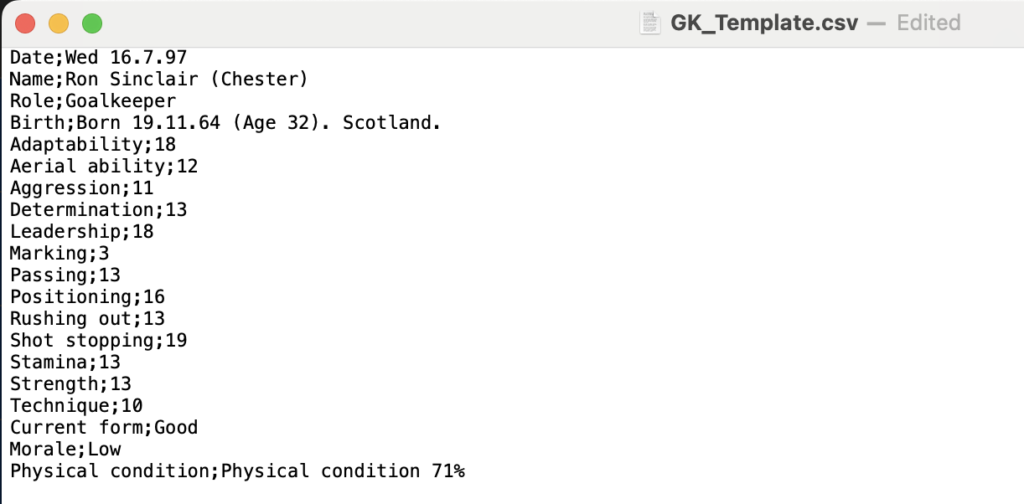
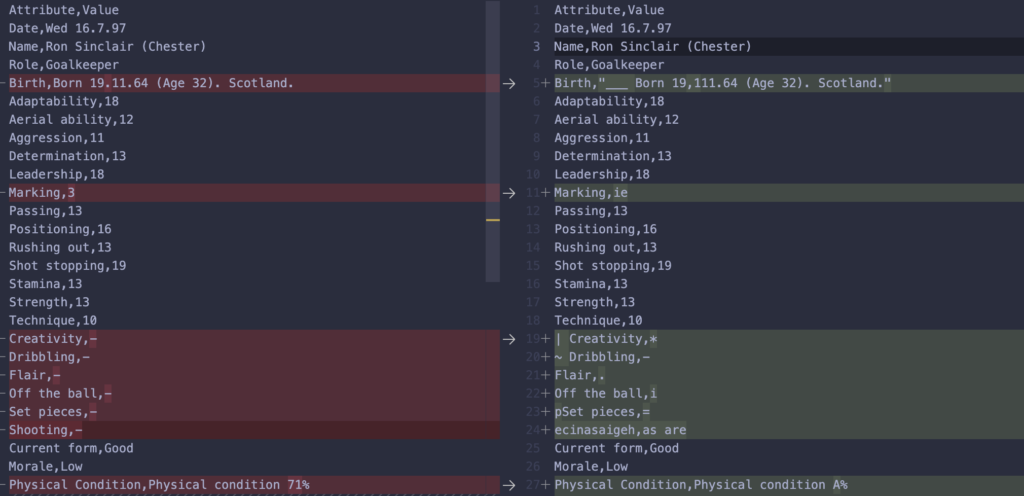
Come si può notare riempiamo una variabile matrix, una matrice che poi utilizzero per scrivere il file stesso. Il file generato contiene l’estrazione completa, confrontandola con la desiderata notiamo delle differenze:
Desiderata a sinistra, risultato dell’estrazione a destra
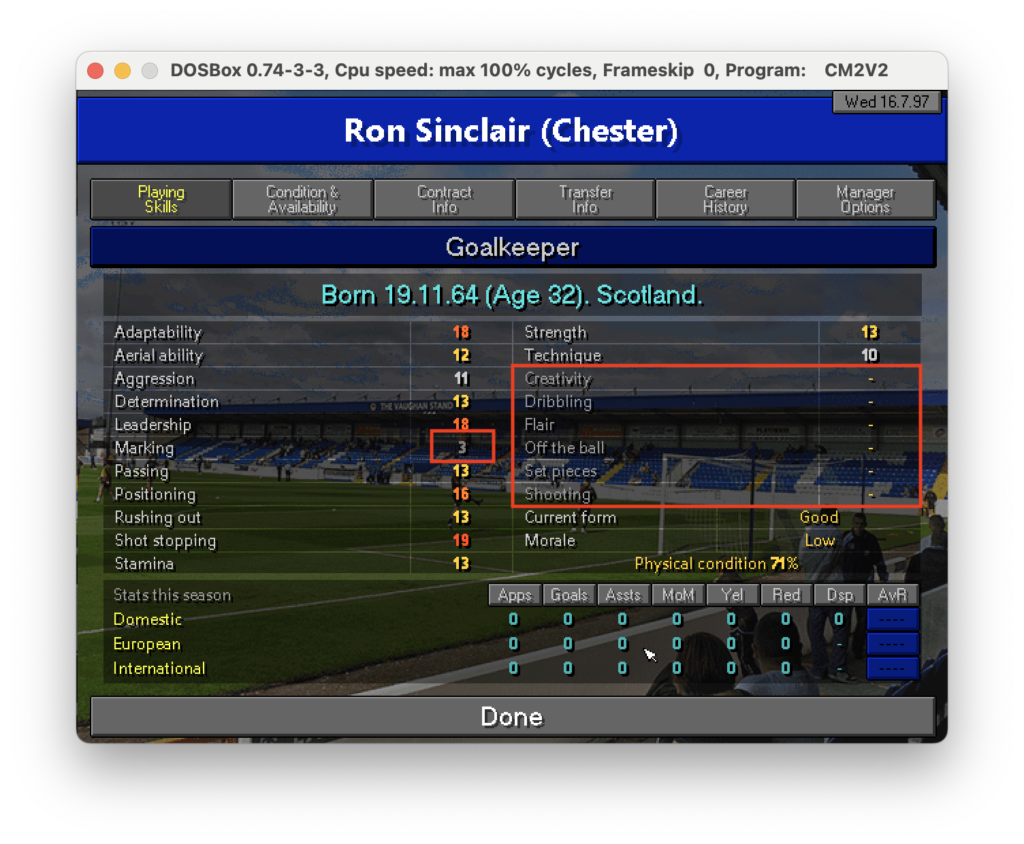
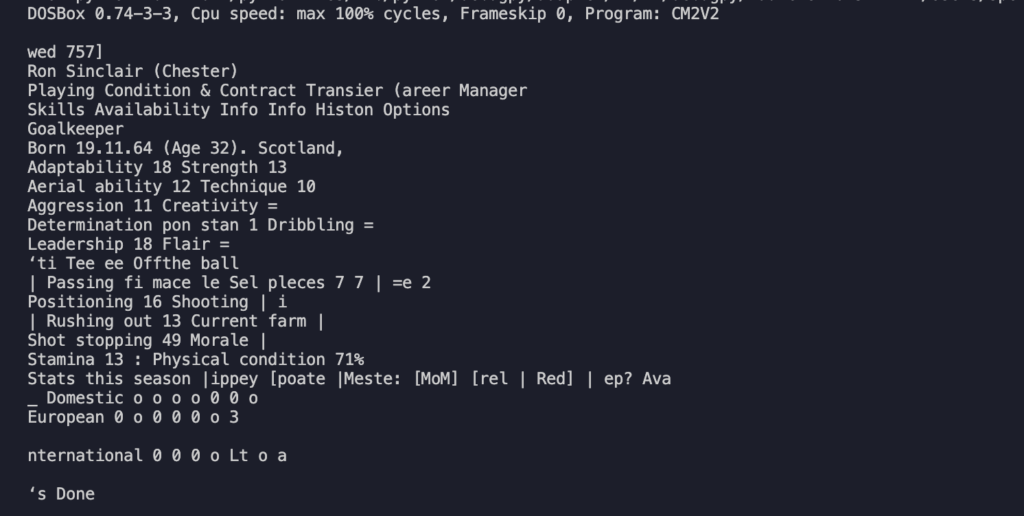
Come si può notare il risultato non è male ma lontano dall’essere perfetto: ci sono molti caratteri speciali che sporcano la lettura come “_”, “*”, “=”. Probabilmente le parti meno riconoscibili sono i trattini “-” e i numeri che hanno un colore del font minore meno pronunciato come quello in Marking 3. Il sistema sembra fare fatica a lavorare dove c’è un contrasto basso. Se guardiamo infatti la figura possiamo notare che tutte le parti che non sono state riconosciute sembrano essere meno evidenti delle altre.
Immagine originale con le parti meno chiare evidenziate in rosso
E’ chiaro che un file così non può essere importato per essere acquisito. L’ideale è capire come migliorare la qualità dell’estrazione, specie per quei caratteri che hanno un basso contrasto. Proviamo a fare una domanda specifica a ChatGPT:
Come posso aumentare l’accuratezza quando il contrasto è basso?
La risposta purtroppo non preannuncia nulla di buono: sembra non sia così semplice . Nel prossimo post analizzeremo le proposte di ChatGPT e proveremo a capire se è possibile migliorare il risultato.
Nello scorso post abbiamo visto come estrarre i testi da una schermata. Purtroppo nel caso analizzato abbiamo molti dati dispersi in vari punti e questo ci ha fornito un estratto difficilmente elaborabile.
Schermata Giocatore
Ciò che gioca a nostro favore in realtà è che il formato del dato è quello per tutte le schermate, ciò che cambierà sarà certamente il nome del calciatore, le info anagrafiche ed i valori delle skills. Fortunatamente la struttura ed il posizionamento sono praticamente identici. In soldoni: sappiamo precisamente dove andare a reperire le informazioni, quindi se ci fosse un modo per restringere il campo potremmo estrarre i dati un po’ alla volta selezionando solo ciò che ci serve.
In rosso alcuni esempi di dati da estrarre
E’ chiaro che sarebbe ideale trovare un modo per estrarre solo le aeree in rosso. Ci sarà? Chiediamo a ChatGPT 🙂
Chiedo a ChatGPT
Notare che ho pure scritto wite invece di write, non volontariamente, è solo un typo, ma vediamo come ci risponde.
Codice Python
Bene, ChatGPT ci espone tutto il codice da utilizzare: viene definita una ROI (region of interest) dell’immagine, viene convertita in scala di grigio e poi infine si estrae il testo così come facevamo anche nel caso precedente. Ok proviamo con un esempio: proviamo ad estrarre il nome del calciatore:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
print(file)
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
x, y, w, h = 110, 140, 1240, 100
#Define ROI
roi = img[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
plt.imshow(gray_roi, cmap='gray')
plt.show()
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(gray_roi)
# Extract relevant information from the data
print(extracted_data)
Come si può notare ho riprodotto fedelmente quanto indicato da ChatGPT, operando qualche accorgimento:
Itero tutti files presenti nella cartella
per ognuno di essi fisso x,y,w,h in modo da centrare esattamente il quadro dove sta il nome
Estraggo il frammento d’immagine con una scala di grigio
utilizzo una libreria per farmi vedere il frammento e capire se è realmente corretto
infine faccio scrivere a schermo il testo
Il risultato è questo:
Risultato acqusizione
Questo è indubbiamente il risultato che mi serve: qui il testo è stato estratto correttamente e può ora essere utilizzato per qualcosa di più strutturato. Purtroppo la parte più ostica è quella di estrarre delle coordinate corrette in cui trovare il testo che ci serve. Andando per tentativi diventa quasi impossibile, quindi googlando ho scoperto che è possibile attraverso la libreria pyplot visualizzare l’immagine selezionata, di conseguenza andando per tentativi possiamo definire pezzo per pezzo le aeree in cui operare l’estrazione effettiva. A questo punto non ci resta che definire pezzo per pezzo dove prelevare i dati che ci servono, estrarli ed in qualche modo convogliarli in un file di ouput che possa essere utilizzabile per aggregare i dati dei vari giocatori.
Nel precedente post al fine di provare ad acquisire e aggregare dati provenienti da schermate di un video gioco anni novanta abbiamo chiesto a ChatGPT di darci una mano nel compito essendo neofiti totali. La scorsa volta ci siamo fermati all’installazione di Python, ora passiamo a Tesseract.
Tesseract
Se proviamo a far girare il codice che ci ha fornito ChatGPT scopriamo che manca un prerequisito che è Tesseract. Ma cos’è esattamente?
Ecco la risposta sempre di ChatGPT
La risposta di ChatGPT
Bene, Tesseract è un OCR ed è utilizzato per estrarre testi dalle immagini: quello che mi serve. E’ Open-Source, supporta il riconoscimento in varie lingue ed è molto accurato se correttamente “allenato” (interessante). Può essere facilmente utilizzato attraverso API e nello sopecifico per sessere tuilizzato in Python necessita della libra “pytesseract”. Direi che è esattamente quello che mi serve. Per installare Tesseract basta un semplice comando con brew [1]
brew install tesseract
Inifine come suggerito da ChatGPT installo anche il wrapper per Python.
pip install pytesseract
A questo punto possiamo cominciare a lavorare sul codice Python per capire come adattarlo e ricondurlo a quelle che sono le mie necessità.
Primo ciclo di codice
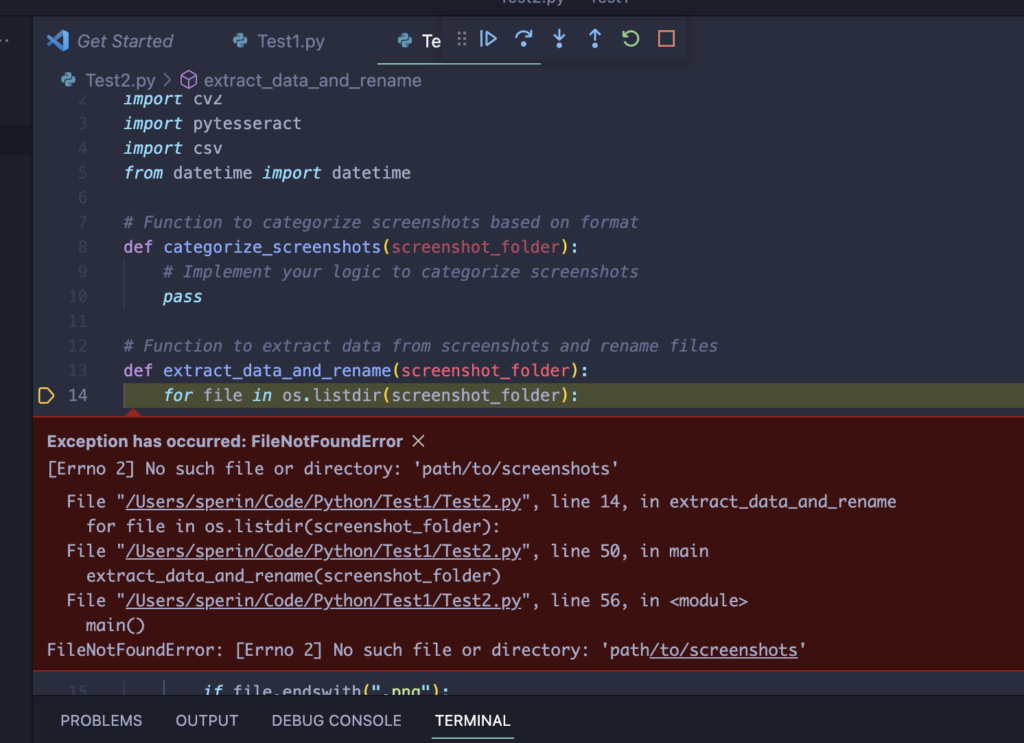
Apriamo Visual Studio Code e creiamo un file vuoto Test.py e copiamo il codice suggerito nel post precedente quindi lanciamo l’esecuzione dal menu Run > Start Debugging. Questo è il risultato:
Primo lancio
L’esecuzione va in errore e la modalità debug di Visual Studio Code ci aiuta evidenziando dove sta il problema: certo devo fornire un path corretto dove prelevare gli screenshots. Al netto di questo errore comunque il setup sembra corretto possiamo quindi dedicarci alla parte più divertene: vale a dire scrivere il codice. Anzitutto faccio un po’ di pulizia: rimuovo la parte che fa la categorizzazione perchè al momento non so ancora come poterla implementare e lo stesso faccio con la funzione che scrive il csv. Infine fornisco il path dove ho già preparato alcuni screenshots da cui estrarre il testo che mi serve. Il main dopo questo restyling è molto minimale:
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = ""/Users/xxxx/ScreenCapture""
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)
Infine mi dedico alla funzione principale extract_data_and_rename che chiaramente itera i files nella cartella e tramite pytesseract estrae il testo dell’immagine. Al momento però mi limito a fare un print del dato estratto:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
print(extracted_data)
Ok ci siamo se lo lanciamo teoricamente dovrebbe iterare tutti i files png presenti nella cartella e scrivere il contenuto estratto da ognuno di essi a schermo. Per questa prima prova uso una sola immagine:
Immagine sorgente
e questo è ciò che il sistema è stato in grado di interpretare:
Testi estratta dallo screenshot
Beh, diciamo che come primo test è già qualcosa però è evidente che alcuni testi sono stati correttamente interpretati mentre altri vanno rivisti. C’è parecchio da lavorare!
Qualche giorno fa in questo post [1] parlavo dei temi relativi all’AI e le sue differenze con la pura automazione. Come esempio pratico vorrei provare ad acquisire in automatico i dati provenienti da alcune immagini e convogliare queste informazioni in un excel. Dovete sapere che io sono un grande amante dei giochi degli anni ottanta e novanta. E voi direte che centra questo? Uno dei giochi sul quale ho perso letteralmente le notti quando ero poco più che un teenager era Championship Manager (Scudetto nell’edizione italiana). E’ stato il primo gioco a fornire una simulazione di ottimo livello del manager calcistico. Sono passati gli anni, sarà l’età avanzata, sarà del sano romanticismo, ma ancora questo gioco riesce a toccare corde cui i giochi strafighi di oggi difficilmente riescono a sfiorare. Se non lo conoscete vi invito a fare un giro su questo sito [2] dove potete addirittura scaricare il gioco (nella versione 97/98) e con dosbox [3] un simulatore di DOS potete persino giocarci. Ebbene una delle cose che ho sempre desiderato fare è avere uno scarico dei dati di giocatori e partite per poterli incrociare avere delle statistiche da cui possibilmente evincere trends ed informazioni utili a schierare le formazioni migliori.
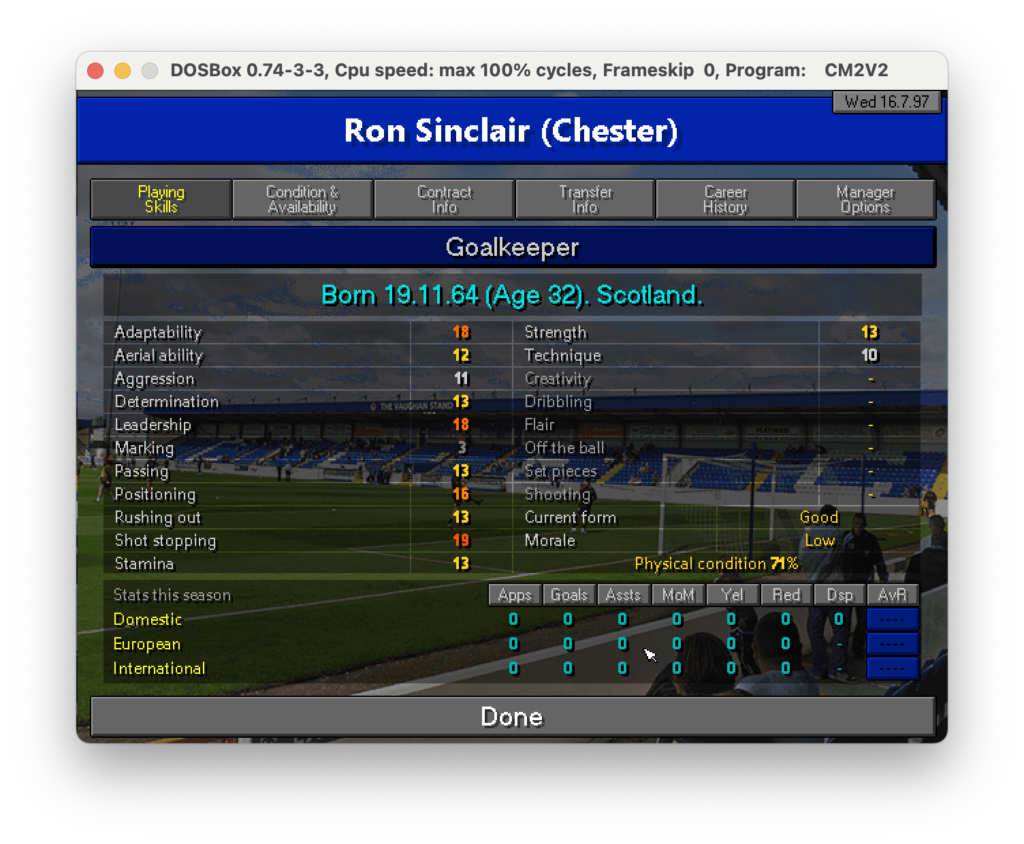
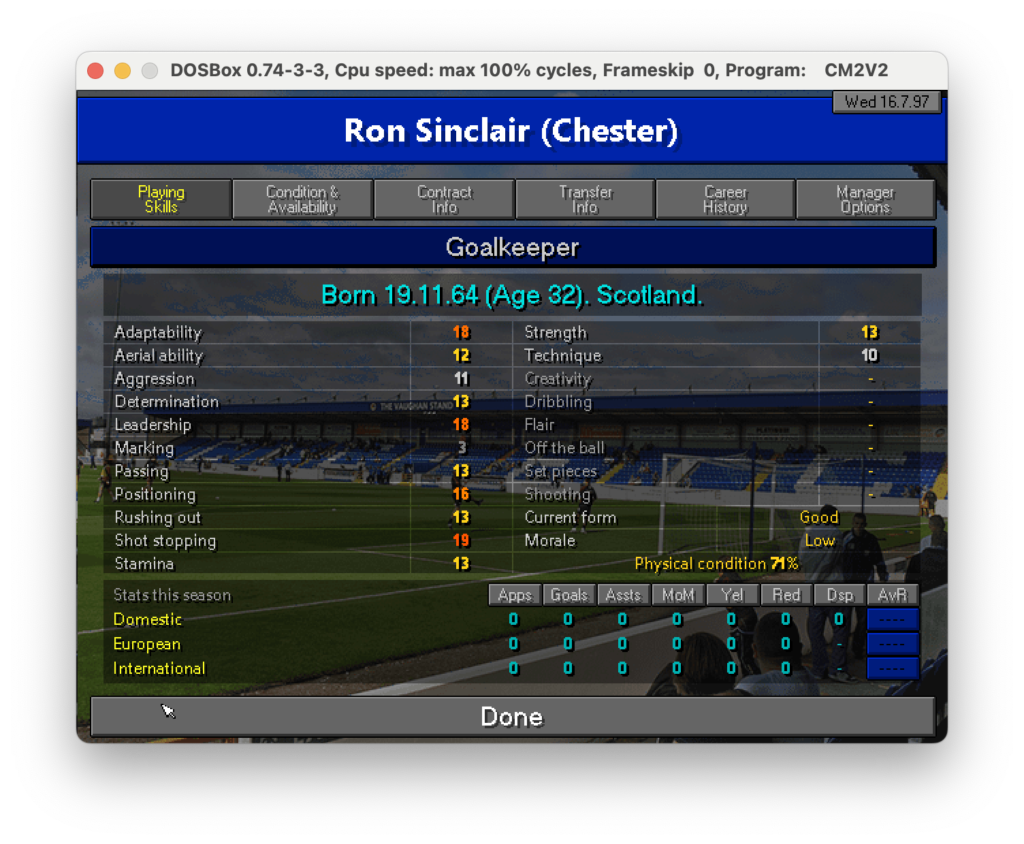
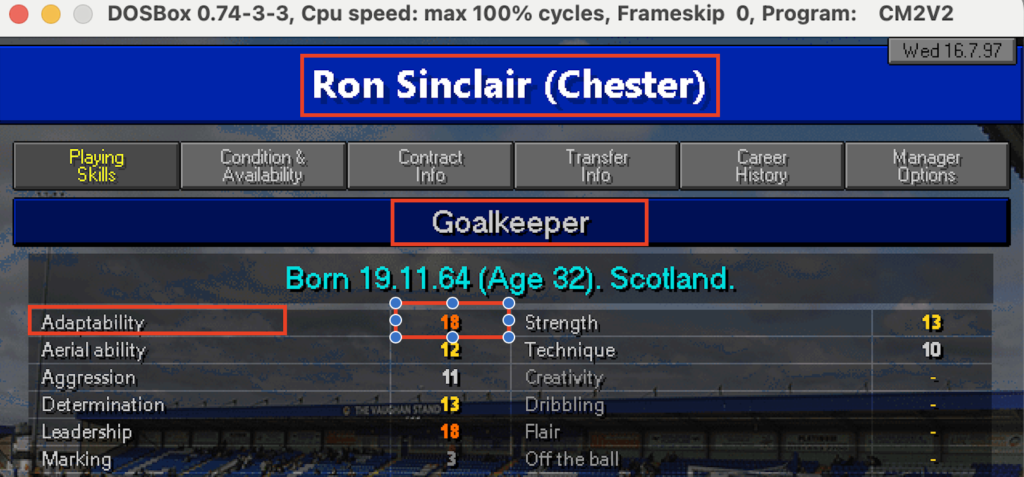
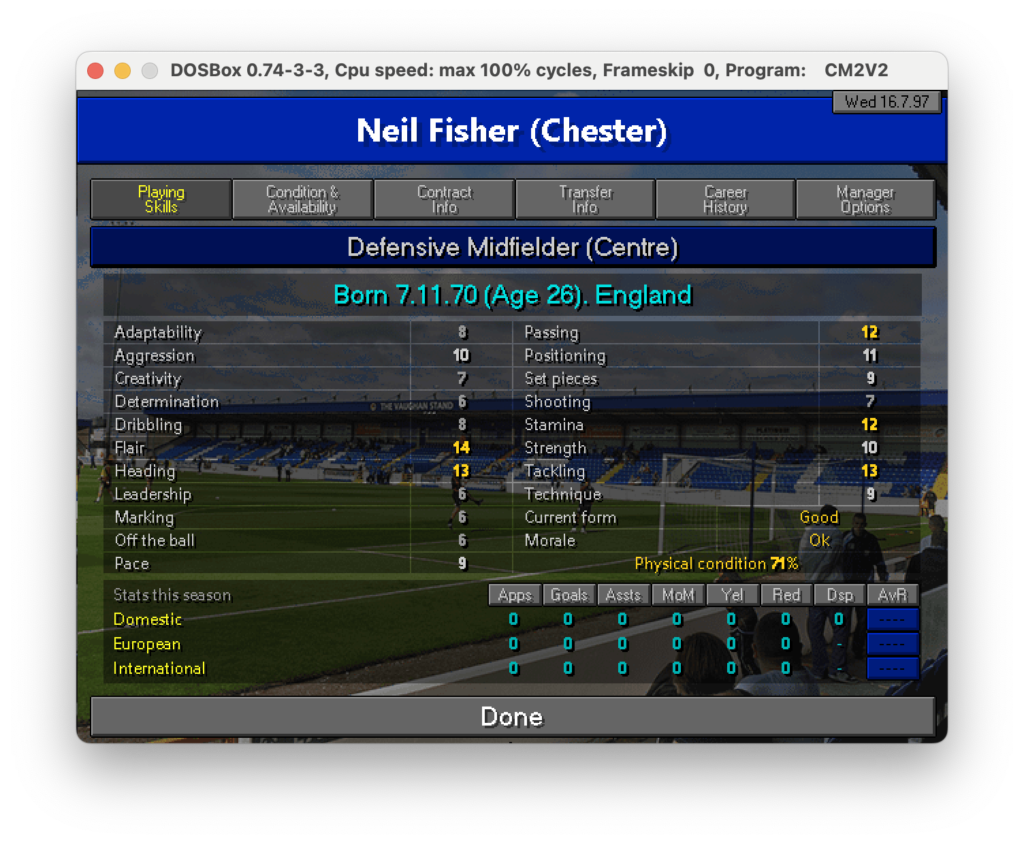
Una schermata di esempio è quella delle skills di un singolo calciatore in cui ci sono info anagrafiche e capacità tecniche
Scheda calciatore
Nella fattispecie mi piacerebbe quindi avere in un unico excel le skills per colonna e i giocatori per riga magari indicando anche la data in cui questi dati sono stati raccolti con l’idea di poter monitorare un giocatore anche in giorni diversi nel caso le sue skills migliorino o peggiorino. Detto questo non ho la minima idea di come procedere, quindi chiedo a ChatGPT se mi può dare una mano:
Definizione del requisito
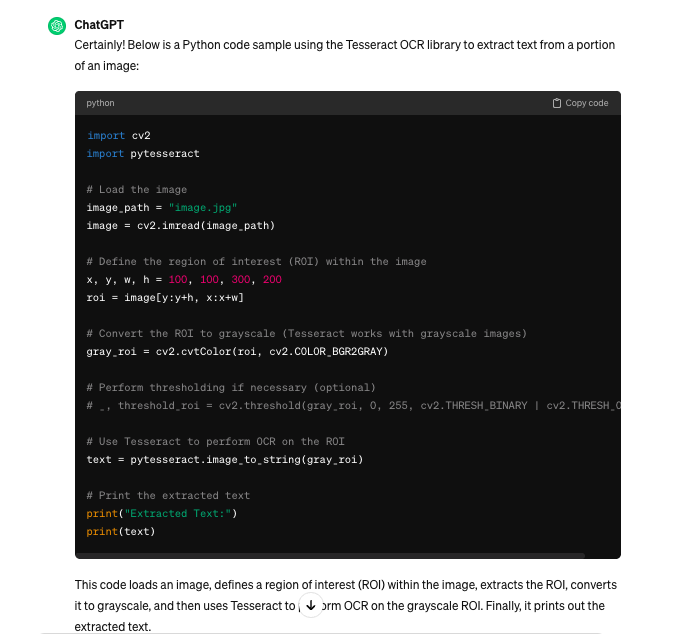
Chiedo scusa per l’inglese maccheronico, ma penso si capisca abbastanza bene. Ed ecco la risposta:
Prima parte della risposta
Bene, diciamo che già la lista delle attività pone sul tavolo alcuni strumenti come Python, OpenCV… In più mi porta cnhe un esempio di codice Python da utilizzare:
import os
import cv2
import pytesseract
import csv
from datetime import datetime
# Function to categorize screenshots based on format
def categorize_screenshots(screenshot_folder):
# Implement your logic to categorize screenshots
pass
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
# Rename the file using extracted data and current date
new_filename = f"{extracted_data}_{datetime.now().strftime('%Y-%m-%d')}.png"
os.rename(img_path, os.path.join(screenshot_folder, new_filename))
# Function to fill CSV files with data from screenshots
def fill_csv_files(screenshot_folder, csv_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
extracted_data = pytesseract.image_to_string(img)
# Write extracted data to CSV file
csv_filename = file.replace(".png", ".csv")
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerow(extracted_data.split("\n"))
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = "path/to/screenshots"
# Path to the folder where CSV files will be stored
csv_folder = "path/to/csv_files"
# Categorize screenshots
categorize_screenshots(screenshot_folder)
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)
# Fill CSV files with data from screenshots
fill_csv_files(screenshot_folder, csv_folder)
if __name__ == "__main__":
main()
Fantastico: non avevo idea da dove cominicare e ChatGPT mi ha dato delle indicazioni preziose per cominiciare ad approfondire i temi.
Python
Non conosco questo linguaggio se non per sentito dire: non ho mai scritto mezza riga di codice, ma mi sembra di poter dire, dall’esempio che riporta ChatGPT, non sia poi così complesso. Leggendo su Wikipedia [4] tra l’altro scopro che deve il nome ai Monthy Python, già questa la dice lunga. Installarlo non è complesso basta seguire gli step indicati nelle varie guide online (tipo questa [5]). Anzitutto verifico che non sia già presente con questo comando a terminale:
python --version
Nel mio caso il risultato è quello che vedete (io ho installato la versione 3)
Bash
Nel caso non lo abbiate installato potete seguire la guida utilizzando brew
brew install python
Ora che Python è finalmente installato possiamo aprire Visual Studio code e utilizzando il codice che ChatGPT ci ha fornito creiamo un file .py di test da eseguire.
Nel prossimo post vedremo le librerie da utilizzare in Python così come ce le ha suggerite ChatGPT.
Arriviamo
alla gara con il Maccesfield in piena emergenza: Preece non ha ancora
recuperato mentre Marshall, Walker e Harsly hanno speso tutto nella gara di
mercoledì. Devo fare qualche azzardo. Alla fine opto per mettere due terzini
come esterni di centrocampo: Akhmedov a sinistra e Blamey a destra. In attacco
ci sono Ormondroyd e Forrester. La partita inizia subito male, dopo venti
minuti perdiamo 1-0. Con l’assetto corrente non riusciamo a combinare granchè e
ad inizio secondo tempo tolgo il solito apatico Akhmedov ed inserisco Marshall
sulla destra spostando Blamey sulla sinistra. Riusciamo a guadagnare campo ma
anche l’inserimento di Harsley non dà profitto. Finisce 1-0 ed al solito, loro
ci hanno fatto gol con l’unico tiro in porta…. Il mercoledì dopo c’è il
Rotherham per il second turno del Windscreen Shield. In attacco è un vero
disastro 3 giocatori su 4 sono in infermeria. Perdiamo 3-0 e siamo fuori.
3 Infortunati su 4 in attacco
Il sabato
giochiamo il secondo turno di FA Cup e vinciamo 4-1 contro lo Stalybridge.
Doppietta di Ormondroyd e reti Preece (MoM) e di Crosby. E’ stata una
passeggiata, il prossimo turno ci sarà l’Ipswich Town di prima divisione: sarà
dura.
Finalmente un po’ di riposo e qualche giorno in più per recuperare nerbo. Giochiamo l’ultima di andata in casa contro il Bristol C sotto di noi di soli 4 punti. Dominiamo ma non centriamo mai la porta e finisce sostanzialmente 0-0. Senza Harsley e Mainwaring purtroppo se non ci pensa il vecchio Ormondroyd non si riesce mai ad infilare la porta…
Dopo la scorpacciata di partite casalinghe mi preparo alla gara in trasferta sul campo del Barnet. Nel frattempo mi arriva un’offerta per Sertori, la situazione finanziaria è abbastanza disastrosa, ma non posso privarmi del migliore difensore in termini di contrasti e colpi di testa. Tengo duro, rifiuto. Vista la situazione economica rinnovo Marshall, Hope ed Ormondroyd che erano tra i giocatori in scadenza di contratto. Non posso permettermi di perderli. Restano ancora 5 giocatori in scadenza: Walker, Clarke, Housham, Wilcox e Shakespear. Clarke e Housham non saranno di sicuro rinnovati. Wilcox certamente se lo meriterebbe mi lascia solo un po’ perplesso l’età (ormai 34)…
La partita con il Barnet è un mezzo disastro, subiamo con continuità e creiamo pochissimo il risultato è l’unica cosa salvabile: 2-2. Non un gran viatico in vista della prossima trasferta sul campo del Peterborough. Con il Rientro in pianta stabile di D’Auria dietro le punte il duo d’attacco titolare diventa Harsley-Mainwaring. Vinciamo meritatamente 1-0 con un gol proprio di Harsley. Dopo due mesi in cui si è giocato sempre ogni tre giorni finalmente non c’è il turno infrasettimanale. Riceviamo il Darlington e Mainwaring sfodera il primo hattrick della sua giovane carriera: finisce 3-0 con tanto di primo MoM. Ancora una settimana e affrontiamo il Cardiff in trasferta e finisce come spesso è accaduto negli scorsi mesi: 2 tiri 2 goal per loro e noi a sprecare troppo. Il mercoledì successivo nella seconda gara del Windscreen Shield otteniamo un bel 2-2 sul campo del Grimsby che ci consente di chiudere al primo posto nel girone.
Tre giorni
dopo giochiamo il primo turno di FA challenge in casa contro Altrincham, la
partita è molto chiusa e non ci sono molte occasioni: finisce 0-0 dopo i ’90
minuti. Si dovrà replicare tra una settimana.
Il 14 Novembre riceviamo il Northampton poco sopra di noi in classifica, è una di quelle gare dove serve fare punti per mille ragioni differenti. Dopo tre minuti la tegola: Mainwaring si accascia è strappo (credo) al polpaccio. Il Nothampton domina e vince 4-2. Nel dopo partita la cattiva notizia: Andrew sarà fuori 4 mesi…
L’infortunio di Mainwaring
La prossima
gara è la ripetizione della partita con l’Altrincham. Preece è appena tornato
dall’infortunio e non ancora in condizione. Sulla sinistra do’ un turno di
riposo a McAuley e schiero Akhmedov. Il primo tempo scorre senza molte
emozioni. Al 60′ Marshall di testa ci porta in vantaggio. A quel punto
l’Altrincham prova la reazione ed un paio di buoni interventi di Colgan
blindano l’1-0 finale. Il sorteggio ci arride affronteremo il Stalybridge una
squadra delle serie minori: il terzo turno è alla nostra portata.
Il 26
Settembre riceviamo il Lincoln quinto in classifica. Brutto cliente, ma dopo
due vittorie in tre partite sarebbe importante mettere in fila due vittorie
consecutive. La parita rimane in equilibrio sul filo dello 0-0 ma al 72′
andiamo sotto e non riusciamo più a pareggiare. Ormondroyd da mezza punta al
posto dell’infortunato D’Auria è troppo lontano dalla porta. Mainwaring gioca
una buona mezzora senza produrre granchè. Si gioca ogni tre giorni e quindi il
sabato successivo andiamo a giocare sul campo dell York fanalino di coda.
Finisce in goleada, segnano tutti gli attaccanti, Harsley firma persino
doppietta e Preece è MoM. Anche Mainwaring rompe il ghiaccio segnando il primo
gol tra i professionisti. Risaliamo alla 13ma posizione.
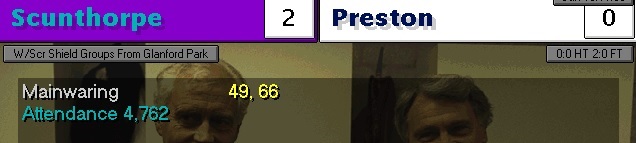
Il mercoledì
successivo va in scena la prima gara del girone del Windscreen Shield e
giochiamo contro il Preston, squadra di seconda divisione. Vista la minore
importanza del torneo rispetto al
campionato opero qualche cambio: posiziono Hope al posto di Wilcox e
Mainwaring dall’inizio a fare coppia con Harsley. Dominiamo la gara e
soprattutto Mainwaring fa doppietta 2-0. E’ nata una stella? La gara successiva
è sul campo del Mansfield. Dopo la pausa rimetto Ormondroyd titolare al centro
dell’attacco con Harsley e tengo Walker a centrocampo optando per un classico
4-4-2. Dopo 2 minuti, Ormondroyd si infortunia e tocca dunque a Mainwaring
prenderne il posto. Vinciamo 2-1 con rete decisiva proprio di Mainwaring, il migliore
in campo è però Colgan. Terza vittoria di fila tra campionato e coppe e
soprattutto 5 vittorie nelle ultime 7 gare e decima posizione in classifica ad
un soffio dalla zona playoffs, che finalmente sia arrivata la svolta?
Teoricamente
il calendario è buono: abbiamo 4 partite casalinghe di fila e con po’ di
fortuna potremmo davvero ingranare un buon passo ed attestarci ad una buona
posizione di classifica. La prima è contro il Rotherham penultimo e dunque
vittima designata. Andiamo sotto quasi subito, Harsley pareggia al 70′ ma 5
minuti dopo Walker commette il più classico degli autogol ed invece di tre
punti facili ci ritroviamo con un pugno di mosche: 1-2. Tre giorni dopo è la
volta del Brighton settimo in classifica. Partita di grande equilibrio come
quella con il Rotherham e ache qui andiamo sotto, recuperiamo con Ormondroyd ma
non è sufficiente e subiamo il 2-1 nel finale. La terza gara è contro il
Shrewsbury sesto in classifica. Finisce 1-1 con il portiere avversario che
prende 9! Di positivo c’è che Mainwaring va ancora a segno. L’ultima della
serie di gare casalinghe è contro il Swansea sopra di un paio di punti in
classifica. Il clichè è pressochè lo stesso delle altre gare: finisce 0-1 dopo
aver avuto anche buone occasioni, probabilmente 1-1 sarebbe stato un risultato
più giusto ma il loro portiere Jones è MoM. Così dopo un un punto in quattro
partite ci ritroviamo di nuovo al 13mo posto in classifica.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Cookie strettamente necessari
I cookie strettamente necessari dovrebbero essere sempre attivati per poter salvare le tue preferenze per le impostazioni dei cookie.
Se disabiliti questo cookie, non saremo in grado di salvare le tue preferenze. Ciò significa che ogni volta che visiti questo sito web dovrai abilitare o disabilitare nuovamente i cookie.