Dopo una prima stagione abbastanza rivedibile, quella 1998/99 potrà essere ricordata come la stagione della riscossa. La squadra dopo essere sempre stata nelle zone alte della classifica conquisterà infatti la promozione in Second Division senza nemmeno passare dai Play-Offs.
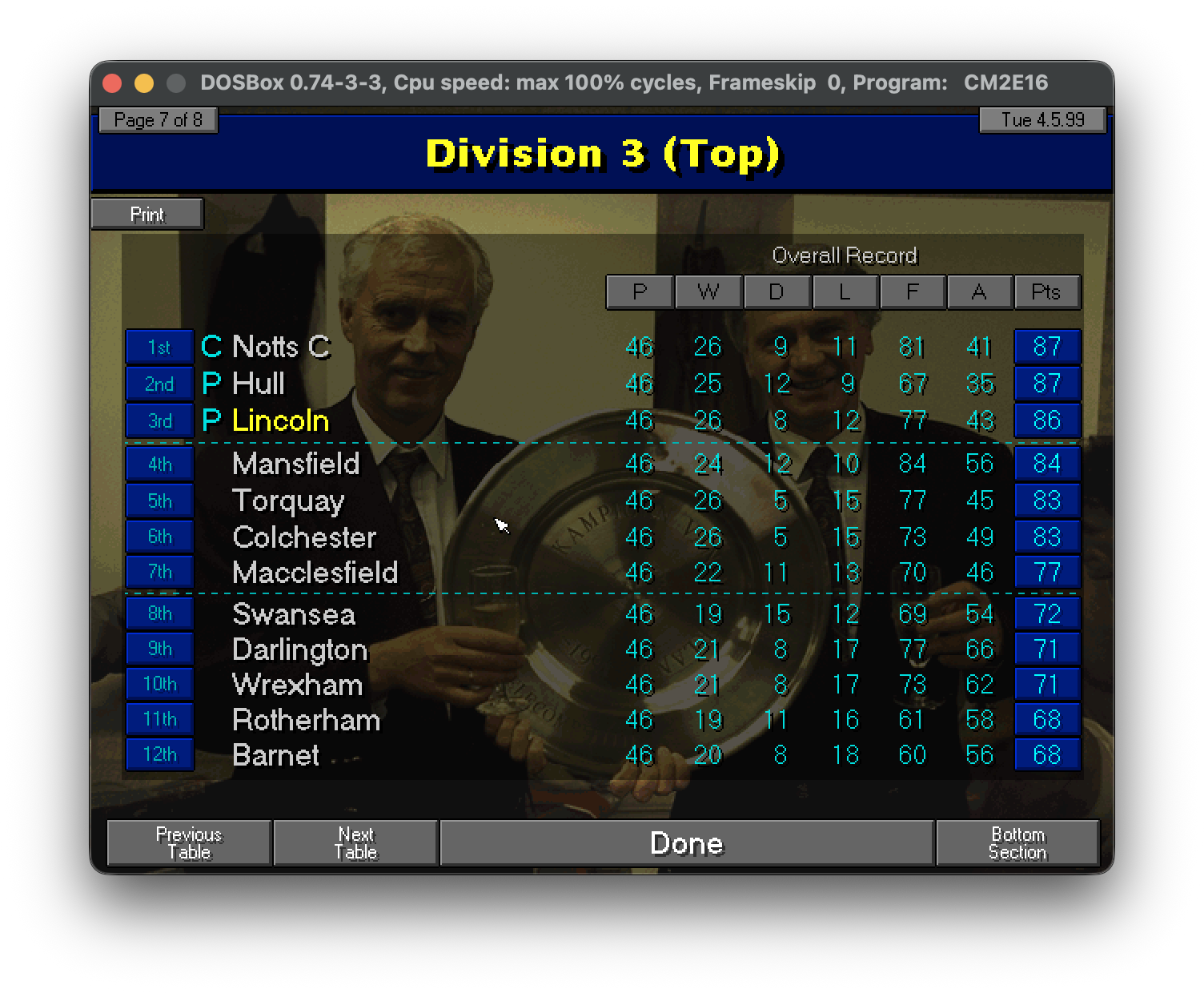
La classifica finale della stagione 98/99
La Stagione
Il campionato comincia a rilento: 2 punti nelle prime tre partite, sembra di rivivere la falsa riga dell’anno precedente in cui per larga parte abbiamo annaspato alla ricerca di una continuità mai trovata. Dalla quarta partita la squadra ingrana invece la quinta (scusate il gioco di parole) e da lì macina risultati su risultati al punto da risalire stabilmente in zona play-offs.
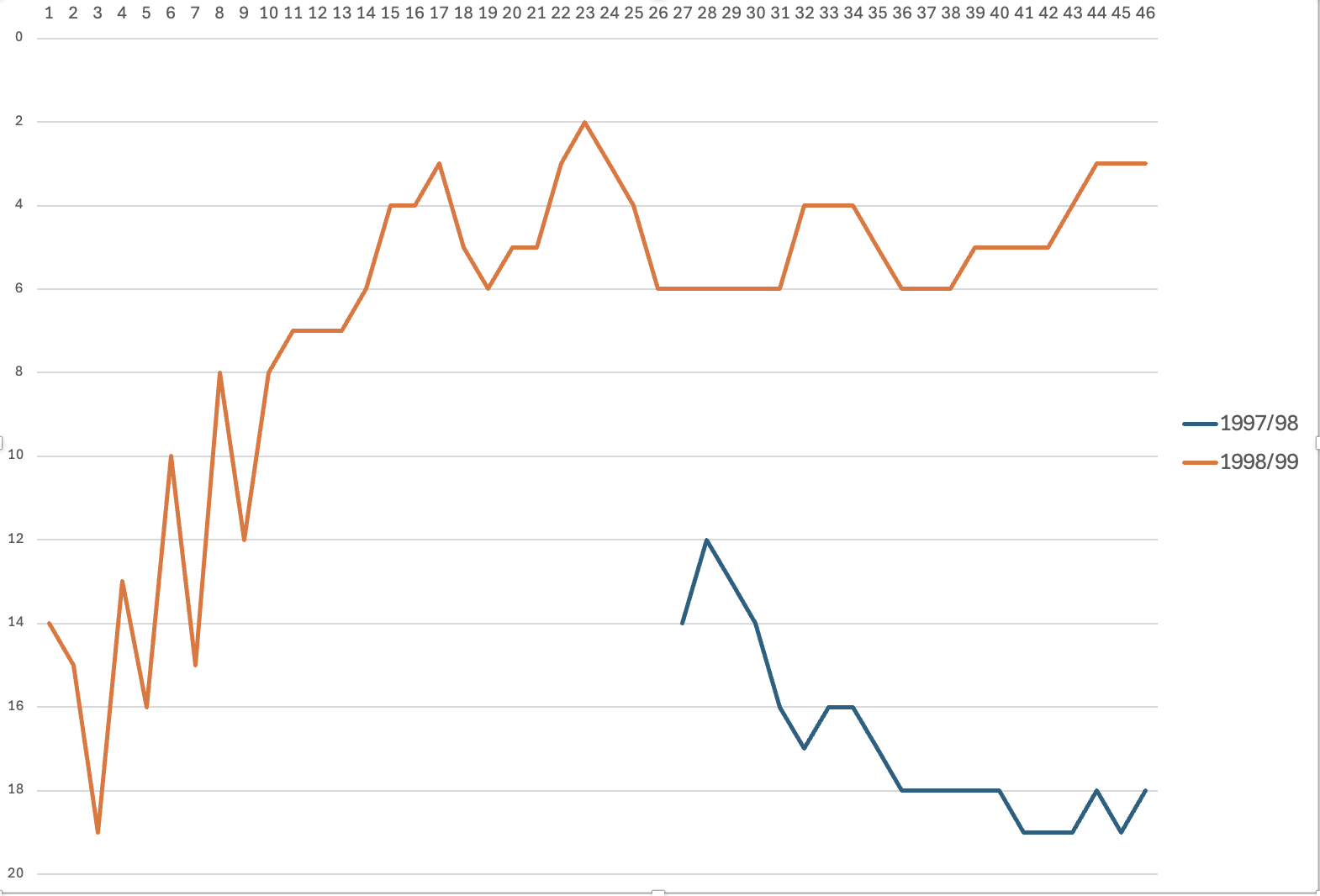
Posizione in classifica nel 98/99
Come si vede dal grafico della posizione in classifica il crescendo è stato continuo. Addirittura per una giornata siamo addirittura stati secondi e cmq dalla 10ma in poi siamo sempre stati in zona playoff.
La Partita
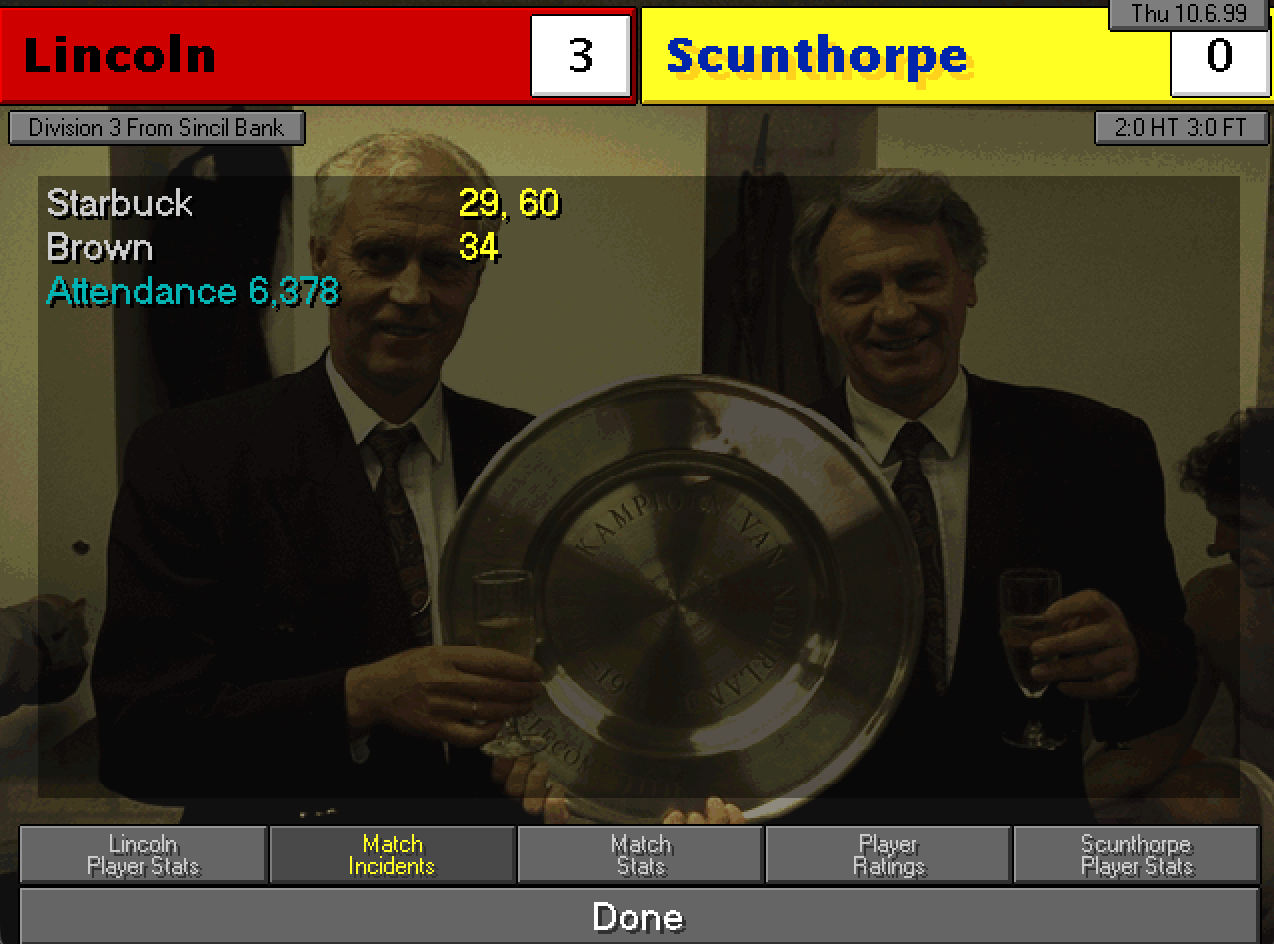
Partita simbolo della stagione è quella dell’ultima di campionato contro lo Scunthorpe: basta un pareggio per terminare nelle prime tre che accedono direttamente alla Second Division. La partita è carica di tensione e nei primi minuti sembriamo essere un po’ in difficoltà per via del peso della gara. Poi però alla lunga viene fuori la differenza tra le due squadre (lo Scunthorpe è in fondo alla classifica) e trionfiamo 3-0.
46ma di campionato che sancisce la promozione in Second Division
Il Giocatore
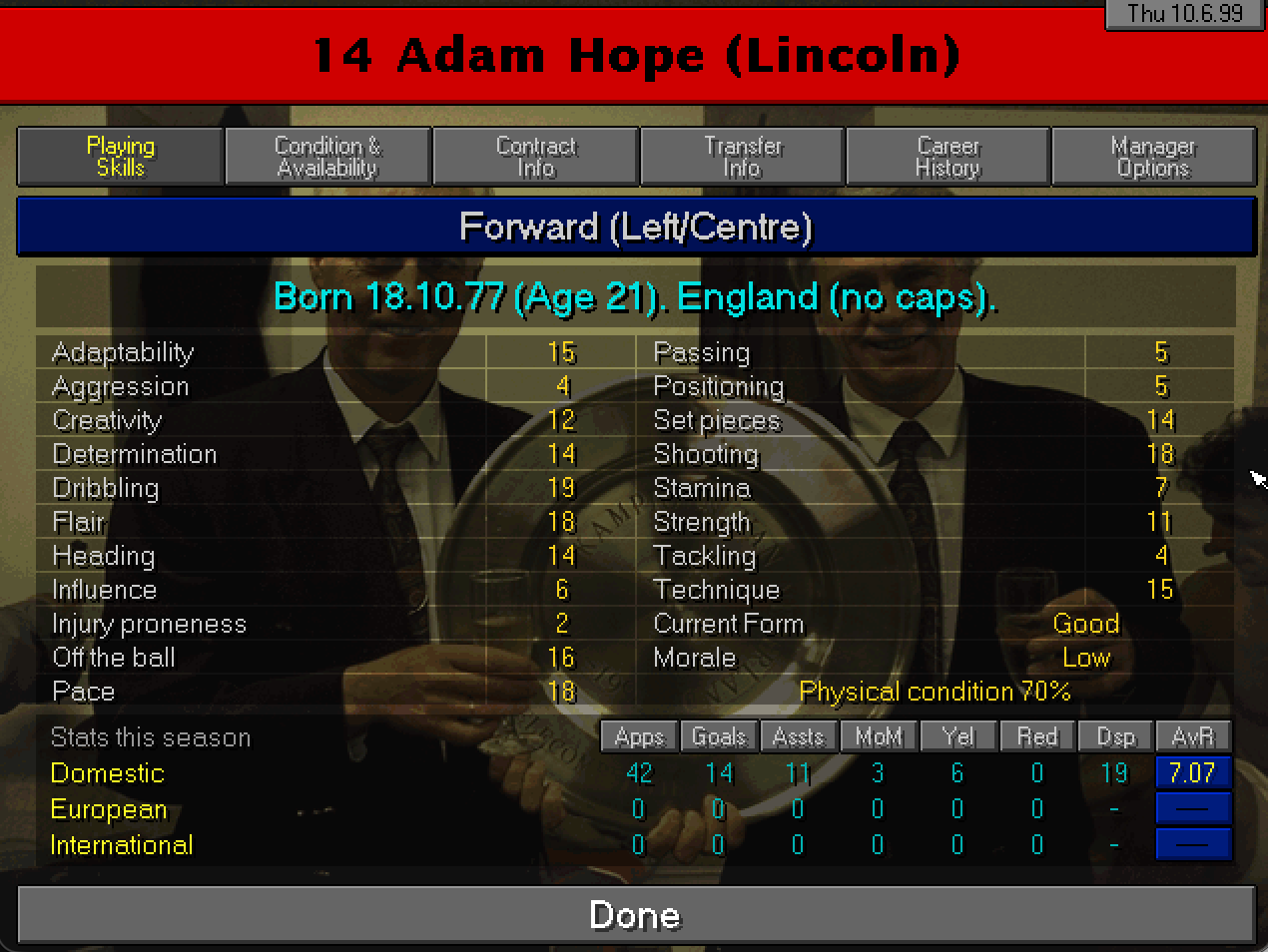
Dovendo fare un nome per la stagione decisamente emerge il nome di Hope un attaccante pescato tra i giocatori senza contratto è diventato quasi subito attaccante titolare: bravo a fare gol e altrettanto bravo a far segnare. Al termine della stagione avrà un valore stimato di 2M, non male per uno preso a zero vero?
Adam Hope
Le Finanze
Anche quest’anno le finanze sono state al centro di tutte le operazioni: in uscita confezionamo 3 operazioni di cui una che porta 1.1M nelle casse con la cessione del portiere Aldus, un plusvalenza notevole dato che anche lui era un parametro 0. Complessivamente quindi la situazione finanziaria è buona. Da notare che anche le entrate relative ai biglietti venduti sono raddoppiate, in linea con quelle che sono state le presenze allo stadio.
Una stagione interlocutoria per ri-prendere le misure con il gioco e fare esperienza
Il Lincoln City è una piccola realtà di Terza Divisione inglese. La società ha un budget molto risicato (appena 150K£ di disponibilità per fare mercato) e un roster malamente assortito, con intere zone del campo non coperte: non ci sono centrocampisti centrali di ruolo, ed altre invece con molti doppioni che rendono complicato riuscire a schierare una formazione con diversi giocatori fuori ruolo. Purtroppo fare mercato per migliorare la rosa non è facile con i pochi soldi che hai e se in più consideri che sei una squadra di modeste ambizioni: in pratica non ci vuole venire nessuno…
La Stagione
Malgrado le premesse, la stagione comincia molto bene: delle prime 5 giornate di campionato ne vinciamo ben 4, riuscendo anche, per qualche giorno ad essere primi in classifica grazie anche al fatto che non tutte le squadre siano a pieno numero di partite. Tra qualche alto e basso si arriva alla 12ma giornata in cui abbiamo collezionato 7V, 2P, 3S ed una posizione da pieno play-off, niente male non è vero? Beh, da lì, per vincere un’altra gara si dovrà attendere quasi 2 mesi… La squadra tra la fine di Settembre e Novembre si è come bloccata, i giocatori che prima sembravano delle certezze, spariti oppure deboli copie degli originali, insomma un bel dilemma. Da quel momento in poi è cominciata una picchiata in classifica che ha toccato il fondo solo al 19 posto. Unica nota positiva è che delle ultime 4 ne vinciamo 5. Ciò che mi porto a casa da questa stagione è che la squadra quando ha giocato i moduli base ha tratto quasi sempre migliori risultati di moduli custom improvvisati sui giocatori. Chiudiamo la stagione al 18mo posto, risultato non eccelso per quanto la dirigenza si sia mostrata tutto sommato contenta.
La Rosa
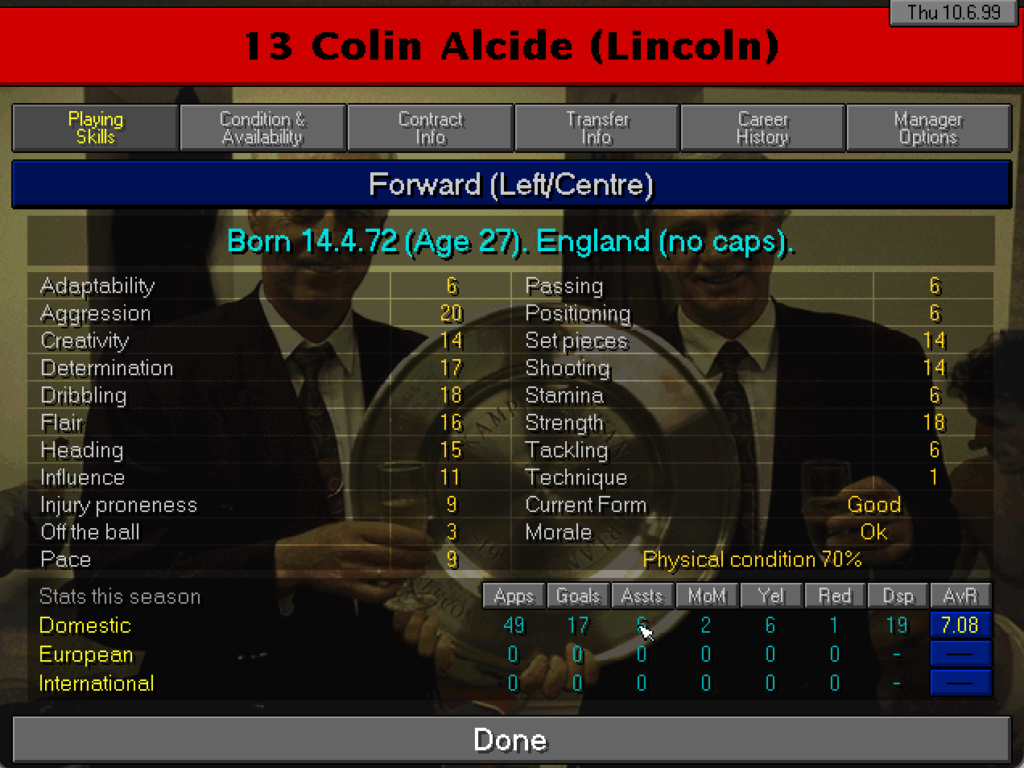
Nel contesto di una stagione complicata mi sento di nominare un paio di giocatori come tra quelli che hanno fatto sentire maggiormente la loro presenza. Il primo Alcide è un attaccante molto tecnico che ha giocato spesso nel 4-4-2 come centrocampista centrale con ottimi risultati sotto porta. L’altro Aldus è un portiere giovanissimo recuperato tra i giocatori senza contratto. Molto giovane, si è guadagnato quasi subito il posto da titolare ed entro la fine della stagione ha raggiunto un valore di mercato di 1M.
Colin Alcide
Le Finanze
Dal punto di vista economico la stagione è stata un vero supplizio: a Luglio c’era una disponibiltà di 150K che però si sono consumati rapidamente, viste le scarse entrate e soprattutto gli stipendi da pagare. Questo ha comportato che durante la stagione abbia dovuto rinunciare a parecchi giocatori per riuscire a coprire le spese.
Questa è stata certamente la prima estate vera con Edo. Quella passata era poco più che un soprammobile: mangiava, dormiva, piangeva e poco più. Dovevi, certamente, dargli un occhio, non potevi uscirtene quando ti pareva ma, certamente abbiamo trovato facilmente spazio anche per del sano riposo e non solo perchè eravamo in montagna.
Quest’anno lo scenario è stato ben diverso: Edo ha concluso il nido al 31 Luglio e dà lì siamo stati per praticamente tutto Agosto h24 tutti insieme. Bello, ma impegnativo e non poco. Aggiungiamo inoltre che da Luglio ha cominiciato a provare a fare qualche passo insolitaria, pochi metri in realtà e sempre con l’obbiettivo chiaro di mamma e papà da raggiungere. Questo ha aggiunto pericolosità al gattonamento prolungato che già aveva perchè la precaria instabilità della camminata ha richiesto ulteriori occhi ed attenzioni. E’ stata anche l’estate del primo bagno (l’anno scorso ci eravamo stati a fine Settembre quando il bagno non era fattibile al di là poi delle sue condizioni post ricovero) e soprattuto della prima sabbia.
La prima tappa è stata a Pesaro dove abbiamo pernottato in una bella casetta praticamente sul mare: si doveva solo oltrepassare una strada, che peraltro sembrava Corso Vercelli la vigilia di Natale. Edo non ha gradito il primo approccio con la sabbia: ci ha messo 2 giorni prima di metterci un piede dentro ma, diciamo che una volta rotto il ghiaccio il problema era levarlo dalla spiaggia. Anche per il bagno ci sono voluti un paio di giorni di adattamento, in sostanza la ciambella con mutandina della decathlon gli ha subito tolto il timore e gli ha fatto gradire l’acqua.
La seconda tappa è stata più a sud, vicino a Vasto Marina, in un resident più moderno e meno spartano della casa di Pesaro, ma certamente le comodità con un bambino molto piccolo si fanno sentire. Il terrazzo gigante in particolare era davvero grande e confortevole per mangiare e magari trovare qualche ora di relax.
Veniamo infine alla parte più delicata: quanto vi siete riposati? Poco, decisamente poco, inutile girarci attorno. Edo è un bambino normale (per fortuna) e di conseguenza quando è sveglio è alla continua ricerca di nuove cose, esperienze, contatti, persone (abbiamo conosciuto tante persone con lui come PR) e naturalmente per noi l’impegno è quello di evitare che si possa fare del male e mettere a repentaglio quanto meno le vacanze se non peggio. La scelta poi di stare in case/appartamenti, dove quindi ti devi fare in pratica quasi tutto e di non avere supporti di terze persone (parenti, amici, strutture dedicate) è stata oltremodo impegnativa perchè ha ridotto il tempo del riposo praticamente alla sovrapposizione delle ore in cui lui in effetti riposava. L’unico trucco che abbiamo escogitato è quello di riservarci nella tarda mattinata, dopo il suo pranzo e prima del nostro una mezzora in esclusiva (ovviamente alternati) in piscina. L’abbiamo chiamata “l’ora d’aria”. Questo è stato l’unico momento di evasione e di relax nel vero senso del termine.
Forse la parte più delicata è stata però la cena, essendo infatti, come detto, in semplici alloggi senza servizi specifici ci siamo imposti almeno alla sera di uscire a cena. Beh, tenere Edo al tavolo (seggiolone), senza trucchetti come Tablet o altro ha implicato due cose:
Si cercava di mangiare il più possibile (normalmente quando anche lui mangiava)
Ci si dava il cambio quando lui non voleva più stare al tavolo
E’ stata dura, si indiscutibile, ma sarà un’estate che ricorderemo per tutte le sue scoperte: il mare, la sabbia, la spiaggia, i bagni… Ti accorgi che con i suoi occhi ogni singola cosa è degna di stupore ed attenzione anche per i nostri occhi da adulti annoiati.
Dopo qualche tempo dall’esperienza con lo Scunthorpe finita male, così come il PC su cui ci stavo giocando, nei ritagli di tempo ho cominciato una nuova stagione con un’altra squadra di 3rd Division inglese il Lincoln City. Questa volta ho deciso di riportare in un excel una serie di informazioni che possano venire utili durante il gioco anche per solo temi statistici. Di volta in volta esporrò alcuni di questi fogli excel per spiegare meglio a cosa servono e perchè li utilizzo.
La Squadra
Nel foglio “PL Skills” ho riportato per tutti i giocatori le informazioni princiali quali ruolo, età, nazionalità e skills.
PL Skills
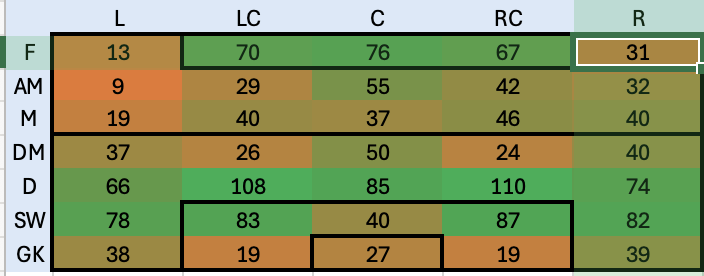
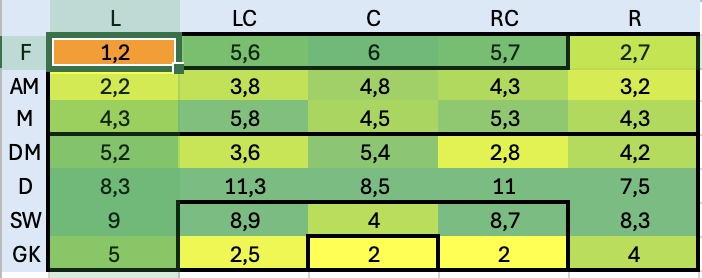
Questa tabella è usata come tabella principale su cui fare lookup per ogni giocatore in tutte le tabelle del foglio excel. In questo modo, anche con l’aiuto del colore (basso -> rosso, alto -> verde) dà già un’idea di massima di come siano distributite le skills ei giocatori. Sfruttando la potenza di PowerQuery mi sono costruito poi una roadmap che in base alle posizioni in campo va a distribuire le skills per dare un’idea di quanto siano coperte le varie parti del campo. il risultato è il seguente:
HitMap Player skills – Punti di forza e debolezza
E’ evidente com la parte di granlunga più debole sia la fascia sinistra ed anche la linea mediana non sembra avere un grosso ricambio. La parte centra dell’attacco e della difesa invece sembrano molto più coperte, probabilmente troppo. Decido quindi di buttarmi alla ricerca di esterni di sinistra che possano coprire meglio quella parte di campo.
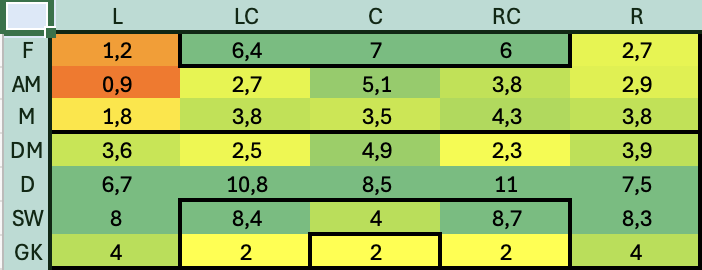
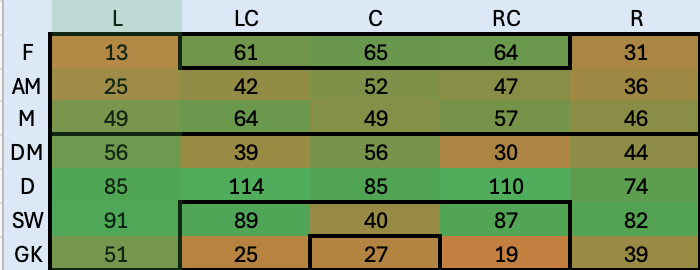
Similmente creo una Hitmap che identifichi la copertura del ruolo in modo da capire anche quelli che sono i ruoli meno coperti, non solo quelli più deboli
Hitmap Player Role Copertura
In questo caso l’indicazione è convergente con quella precedente: la fascia sinistra dalla meta campo in su è fortemente scoperta ed è certamente da rinforzare. Diciamo che da questa analisi ci portiamo a casa le seguenti informazioni:
Nei ruoli d’attacco abbiamo una grande abbondanza: in media abbiamo 6 contendenti per 2 posti (assumo di non giocare con 3 attaccanti)
La fascia sinistra richiede un bel boost
Nei ruoli di difesa, in particolare quelli centrali c’è una grande abbondanza con 10 contendenti per, probabilmente, 2 massimo 3 ruoli.
Precampionato e calcio mercato
Partendo dalle considerazioni di cui sopra organizzo 3 amichevoli precampionato per cominciare a vedere un po’ la squadra e capire con che modulo giocare ma soprattutto quali giocatori preferire.
Precampionato
La prima gara è con una squadra del nostro campionato in trasferta. Per la formazione mi faccio guidare da come è composta la rosa e schiero un 3-5-2 che però non mi convince, perdiamo 2-1 senza molte luci. Al termine di questa gara mi viene fatta un’offerta molto interessante per Baily attaccante 31enne in scadenza di contratto a fine anno. Accetto: in attacco siamo molto coperti ed un modo anche per fare cassa. Per la seconda gara, sempre contro una squadra della nostra division, schiero un classico 4-4-2 adattando un centrale sulla sinistra non avendo giocatori di ruolo: va alla grande vinciamo 4-1 dominando sostanzialmente la gara. A questo punto bollo il 4-4-2 come modulo migliore o cmq più affidabile al momento. In questa settimana riesco a mettere anche a segno un paio di acquisti per la fascia sinistra:
Due nuovi acquisiti
Dopo questi cambi nell’organico le nuove hitmap sono le seguenti:
Nell’ultima gara del precampionato affrontiamo in casa un squadra di Second Division, finisce 0-0 non molte occasioni. Nyamah ha giocato solo il primo tempo senza incidere particolarmente.
Non resta dunque che partire con la stagione che comincia con un trasferta per un mese d’agosto massacrante in cui si giocherà ogni 3-4 gg.
Da inizio Giugno Edo ha messo fuori dalla sua scala di priorità il ciuccio che, se fino a qualche giorno fa era sostanzialmente un compagno fedele in un tutte le fasi della giornata da oggi non lo è più. E’ successo durante una sessione di Mani, bocca, piedi e ad alcuni dentini che lo ha fortemente destabilizzato, in alcuni momenti anche portandolo a regredire in maniera tosta (non gattonava più, praticamente passava le giornate in maniera passiva). Che fortuna! mi dicono un po’ tutti, non avete dovuto imporlo. Si, verissimo, i miei ad esempio hanno fatto una fatica immane a togliermelo ma c’è un contraltare non banale. Ora si addormenta in maniera più traumatica (non riesce a tranquillizzarsi da solo) e soprattutto la mattina capita molto spesso che si svegli molto presto, le 5:30, le 5:40, le 5:50. Insomma, si fanno passi avanti, parecchi a dire il vero ma c’è sempre un prezzo da pagare. Diciamo poi che il caldo di queste settimane non da una mano, fortuna che abbiamo messo il condizionatore, così almeno anche solo col deumidificatore l’ambiente dove dorme è fresco.
Ormai da inizio Aprile si alza in maniera autonoma e se fino a qualche settimana fa, con il nostro aiuto, tenedogli le manine, faceva pochi passi prima di stancarsi, nelle ultime settimane sembra prenderci molto gusto anche se ancora in termini di equilibrio è molto instabile. Stiamo scaldando i motori dunque, ci avvicianiamo al rilascio della nuova versione con la funzionalità camminata.
Una libreria plug&play per implementare l’autenticazione tramite JWT token in .NET 8.0
Quando si creano delle Web API uno dei temi ricorrenti è come gestire l’autenticazione per consentire un uso autorizzato delle funzionalità esposte. E’ infatti poco vero simile che le delle API vengano esposte in maniera totalmente priva di autorizzazione specie se fanno le classi che CRUD che vanno quindi a persistere dei dati su un qualsivoglia tipo di repository. Premesso che sono molteplici le possibilità di implementazione la mia scelta è caduta sul token JWT [1] uno standard che consente di encriptare alcune informazioni chiave in un formato ben definito.
Nel dettaglio listo quelli che sono per me i requisiti chiave:
Tecnologia: .NET 8.0
Database/Repository: MySQL
Formato Token: JWT
Plug&Play: questa libreria potrà essere aggiunta ad una qualsiasi WebAPI .NET e con pochi step di configurazione gestirne l’authenticazione
Nella creazione di questa libreria mi sono basato su questo link [2] che spiega molto bene tutti gli steps principali. Su Github [3] trovate il progetto da cui potete scaricare il codice sorgente.
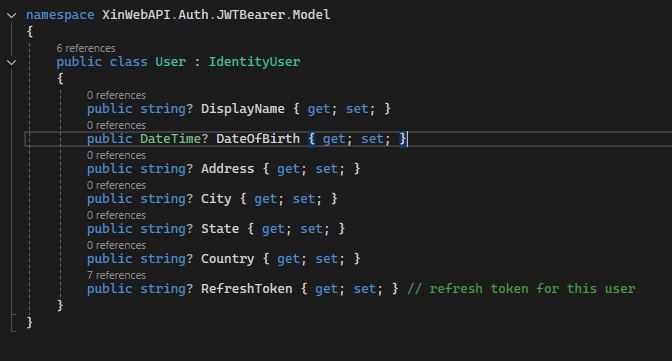
Il Modello
Per questa implementazione sfruttiamo il modulo ASPNETCore.Identity che fornisce già una base sui cui lavorare. Nella fattispecie creiamo una classe User che erediti da IdentityUser estendendone alcune property.
User Model
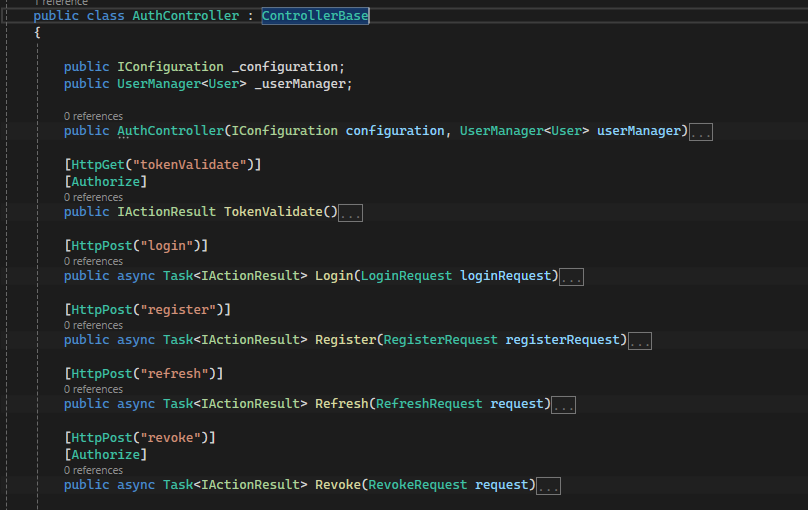
A questo punto implementiamo l’AuthController che sfrutterà parte delle funzionalità fornite dallo User Manager della stessa libreria di cui sopra.
AuthController
Non mi dilungo troppo perchè nell’articolo da cui ho preso spunto è tutto spiegato per filo e per segno ma in sostanza i metodi implementati servono a gestire la creazione del JWT token e il relativo refresh. ATTENZIONE: il refresh token è memorizzato nel campo relativo dello User. Il che significa che quando il token scade chi consuma il servizio può richiedere un nuovo token ricorrendo a questo refresh token senza una nuova authenticazione.
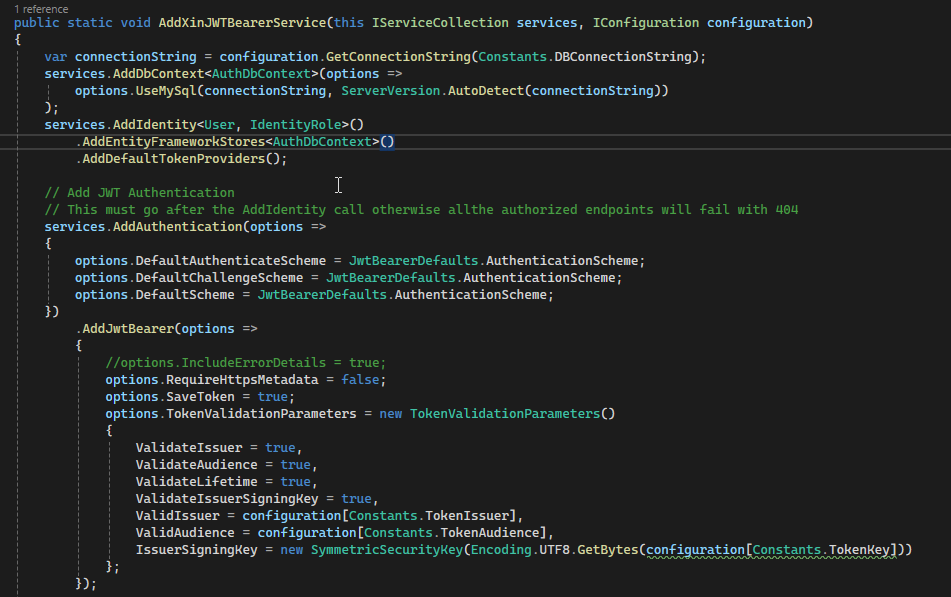
Il Service
Ma come avviene la validazione del Token? Sempre sfruttando la libreria ASPNETCore.Identity andiamo a creare un extension di Service Collection che effettuerà la configurazione del token impostando:
il repository: in questo caso MySQL
lo schema di autenticazione: in questo caso JwtBearer
Service Extension
Come si può notare, alcuni parametri vengono prelevati dal configuraiton e vengono dunque dall’app che sta effettivamente utilizzando la libreria.
Come utilizzarla?
L’utilizzo è molto semplice e verte su questi punti:
Aggiungere la libreria al progetto
Configurare AppSettings includendo:
La connectionstring per il DB MySQL
La sezione del token con tutti i parametri relativi
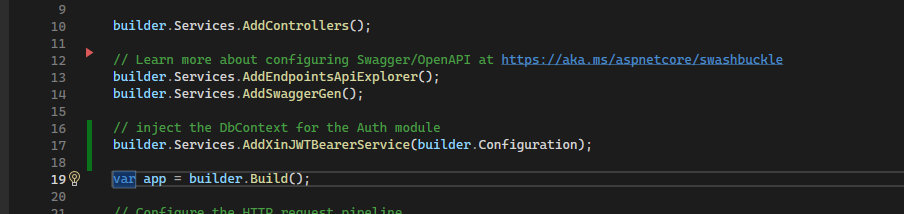
Aggiungere la chiamata al service nel program.cs
Program.cs
Questo dovrebbe essere tutto. Tenete conto che l’implementazione del repository si basa su EntityFramework il che significa che un semplice cambio di API e qualche linea di codice si può estendere facilmente a tutti i repository che abbiano un EntityFramework library che li gestisca.
E’ già trascorso un anno, potrei dire volato in maniera più che letterale, da quando lo scorso anno, il 23 Aprile, Edo è entrato nelle nostre vite cambiandole radicalmente. Non voglio perdermi troppo in analisi su come era il prima e sul cosa sia cambiato poi: mi era ben chiaro che un cambiamento simile avrebbe stravolto tutto. E’ più facile raccontare le notti insonni (ben poche a dire il vero), i pannolini, le pappe, i pianti (anche questi pochissimi) … è molto più complesso invece descrivere ciò che di bello ci sta dietro e che, purtroppo devo essere retorico, solo chi ha realmente provato può capire fino infondo.
Non si è mai pronti per fare il genitore, almeno con i primo figlio, e si deve fare un grande sforzo per accettare i propri limiti e conviverci facendo sempre del proprio meglio senza però farne una ragione di frustrazione. Ricorderò sempre la sensazione strana e anche un po’ preoccupata di non essere più in due in casa ma, di avere un altro esserino con noi che respirava la nostra stessa aria e che dipendeva in tutto e pertutto dalle nostre attenzioni così come dalle nostre mancanze. In certi momenti può essere davvero paralizzante il timore di non fare la cosa giusta, di semplicemente essere inadeguato ma questa può essere la sensazione di un momento non certo uno stato finale. Ho riscoperto in questi mesi che cosa sia l’istinto: un qualcosa che la nostra società evoluta cerca scientemente di governare e incanalare in comportamenti che siano accettabili dal vivere comune e dal comune buon senso. L’irrazionalità che sta dietro all’istinto nelle persone adulte è inevitabilemente relegata ad alcune aree molto ben circoscritte. La presenza di un neonato azzera quasi completamente queste barriere anche perchè: vai a spiegargliele… E’ questo apre davvero un orizzonte completamente diverso, ti porta a doverti mettere in gioco completamente, non solo il tuo tempo libero ma in tutti gli aspetti della vita quotidiana. E’ una riscoperta straniante ma assolutamente affascianante. Osservare mentre tuo figlio smangiucchia un biscotto senza farsi prendere dal panico ogni volta che sembra sul punto di vomitarlo o strangolarsi richiede tanto istinto, tanta serenità, che spesso non sono così semplici da concepire.
Ma torniamo al lato migliore: quanto è bello tenere tuo figlio in braccio? Quanto è bello tenergli la manina mentre prova ad alzarsi oppure quando indica qualcosa di non meglio identificabile? Quanto riempie il cuore il suo sorriso sdentato e quello sguardo candido? Spesso alla sera si è stanchi e si riesce a malapena a trascinarsi verso il letto e vederlo andare a mille tra un pupazzo, una pallina o una macchinina è in un certo senso rigenerante. Avere un bambino, specie per chi non è giovanissimo come me, ti fa guardare al futuro con speranza, con gioia, con attesa, con stupore. Ti allunga la vita accorciandoti le giornate. E’ un miracolo, nel vero e proprio senso del termine.
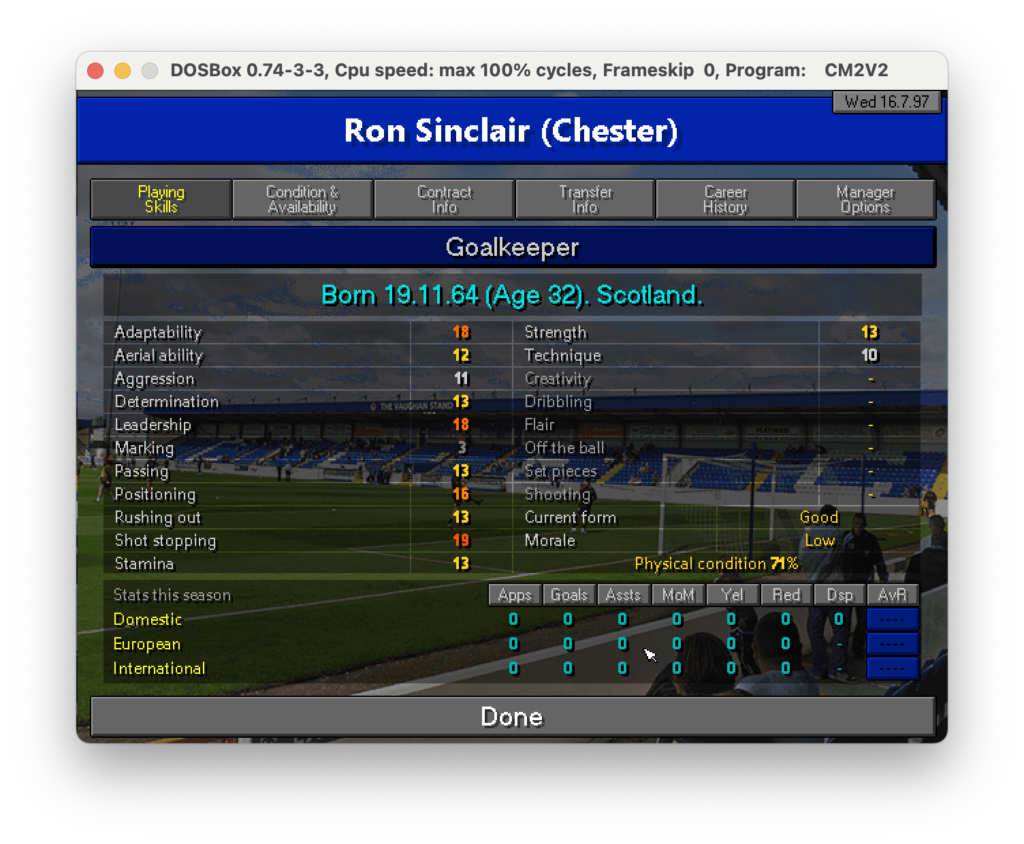
Nell’ultimo post di questa serie abbiamo scoperto come estrarre testo da specifiche parti di un’immagine. Ora, per proseguire nel progetto che ci siamo dati in origine (vedi qui) dobbiamo fare in modo che il dato letto sia correttamente salvato in un file CSV che poi importeremo in seguito. Quindi, ricapitolando: un csv che riporti nella prima colonna il la descrizione del campo come, nome, ruolo e skills e nella seconda colonna il valore di questi campi. Ad esempio nel caso seguente dovremmo partire dall’immagine:
Scheda calciatore
Per ottenere un csv che possa più o meno essere come il seguente:
Esportazione desiderata
Per falro anzitutto creo una funzione Python che mi data un’immagine e le dimensioni in cui è contenuta mi estragga il testo, così evito di dovre riscrivere tutte le volte il codice per estrarle, in più passo come parametro un booleano che, all’occorrenza, mi può anche far vedere l’immagine ritagliata prima di estrarre il testo.
# Function to extract data from a portion of screenshot
def extract_portion_for_csv(x,y,w,h,image,showimg):
roi = image[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
if showimg:
plt.imshow(gray_roi, cmap='gray')
plt.show()
export = pytesseract.image_to_string(gray_roi)
return export
Ora che abbiamo una funzione che estrae il testo da specifiche parti dell’immagine si tratta solo di estrarre ognuna di esse definendo punto per punto dove recuperare il dato. Questa è la parte più noiosa in cui, testo per testo dobbiamo recuperare le coordinate. Per meglio organizzare le cose definisco 2 aree: quella in alto che contiene i dettagli anagrafici del profilo ed una sotto che contiene la parte di skills. Questo frammento estrae la parte anagrafica:
Ad una prima analisi possono sembrare complessi ma in realtà non lo sono: sono semplicemente abbastanza ripetitivi. Per ognuno dei testi che dobbiamo estrarre facciamo in modo di specificare le coordinate e mettiamo tutti i testi all’interno di una matrice così da utilizzarla poi nella scrittura del file csv tramite questo frammento:
def write_to_csv (csv_folder, csv_filename, matrixtowrite):
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerows(matrixtowrite)
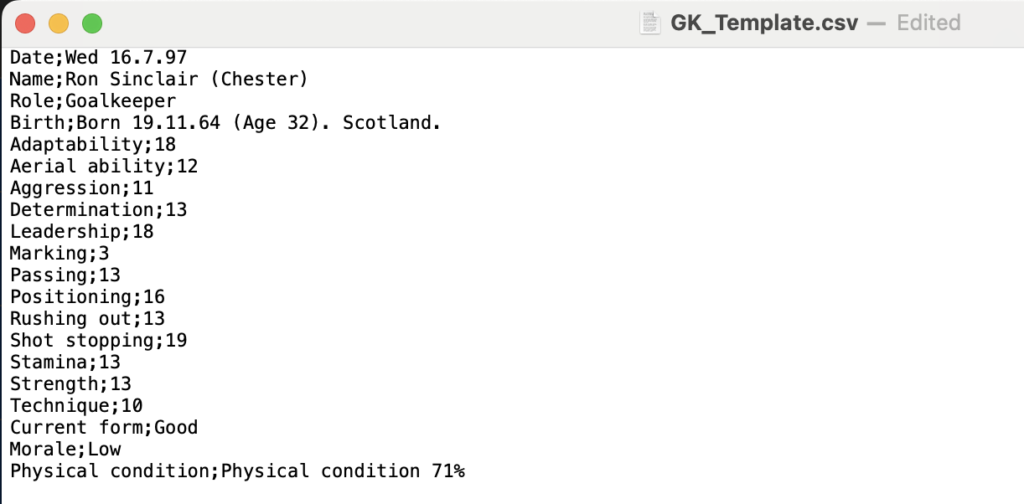
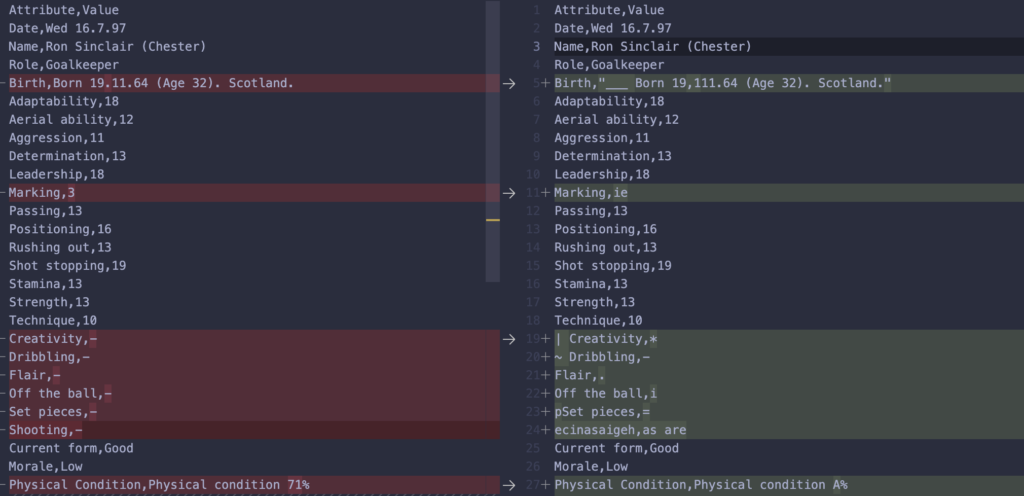
Come si può notare riempiamo una variabile matrix, una matrice che poi utilizzero per scrivere il file stesso. Il file generato contiene l’estrazione completa, confrontandola con la desiderata notiamo delle differenze:
Desiderata a sinistra, risultato dell’estrazione a destra
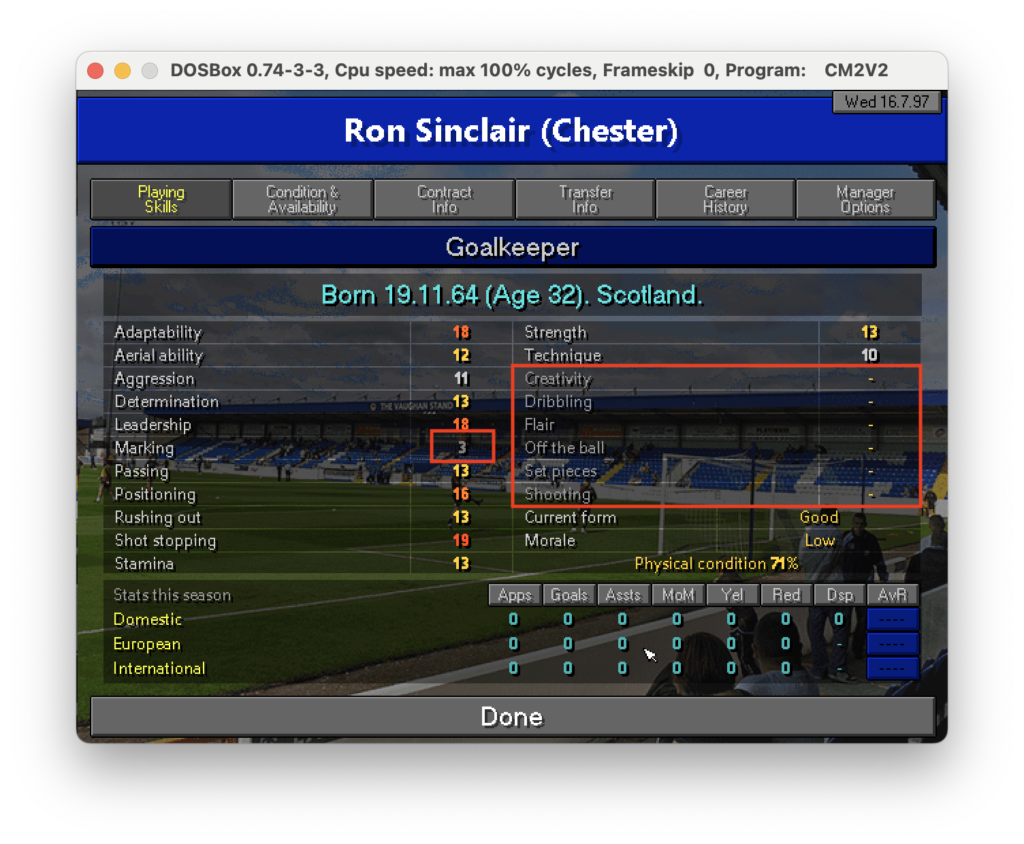
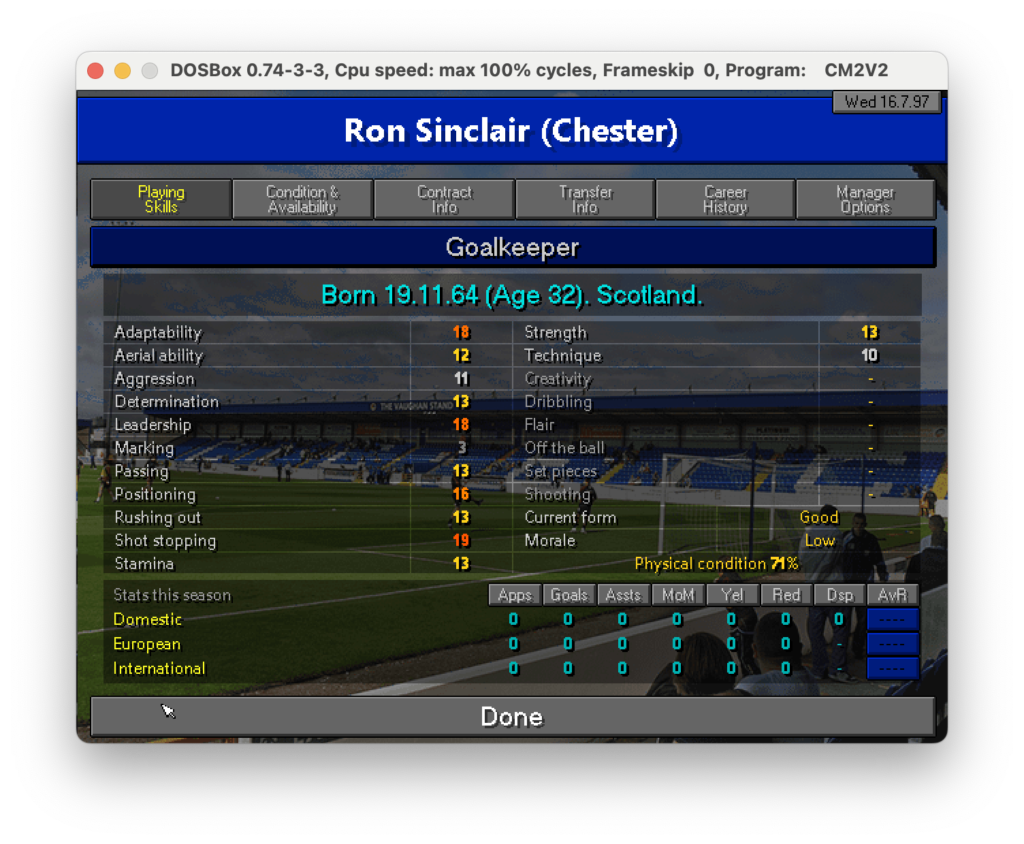
Come si può notare il risultato non è male ma lontano dall’essere perfetto: ci sono molti caratteri speciali che sporcano la lettura come “_”, “*”, “=”. Probabilmente le parti meno riconoscibili sono i trattini “-” e i numeri che hanno un colore del font minore meno pronunciato come quello in Marking 3. Il sistema sembra fare fatica a lavorare dove c’è un contrasto basso. Se guardiamo infatti la figura possiamo notare che tutte le parti che non sono state riconosciute sembrano essere meno evidenti delle altre.
Immagine originale con le parti meno chiare evidenziate in rosso
E’ chiaro che un file così non può essere importato per essere acquisito. L’ideale è capire come migliorare la qualità dell’estrazione, specie per quei caratteri che hanno un basso contrasto. Proviamo a fare una domanda specifica a ChatGPT:
Come posso aumentare l’accuratezza quando il contrasto è basso?
La risposta purtroppo non preannuncia nulla di buono: sembra non sia così semplice . Nel prossimo post analizzeremo le proposte di ChatGPT e proveremo a capire se è possibile migliorare il risultato.
Nello scorso post abbiamo visto come estrarre i testi da una schermata. Purtroppo nel caso analizzato abbiamo molti dati dispersi in vari punti e questo ci ha fornito un estratto difficilmente elaborabile.
Schermata Giocatore
Ciò che gioca a nostro favore in realtà è che il formato del dato è quello per tutte le schermate, ciò che cambierà sarà certamente il nome del calciatore, le info anagrafiche ed i valori delle skills. Fortunatamente la struttura ed il posizionamento sono praticamente identici. In soldoni: sappiamo precisamente dove andare a reperire le informazioni, quindi se ci fosse un modo per restringere il campo potremmo estrarre i dati un po’ alla volta selezionando solo ciò che ci serve.
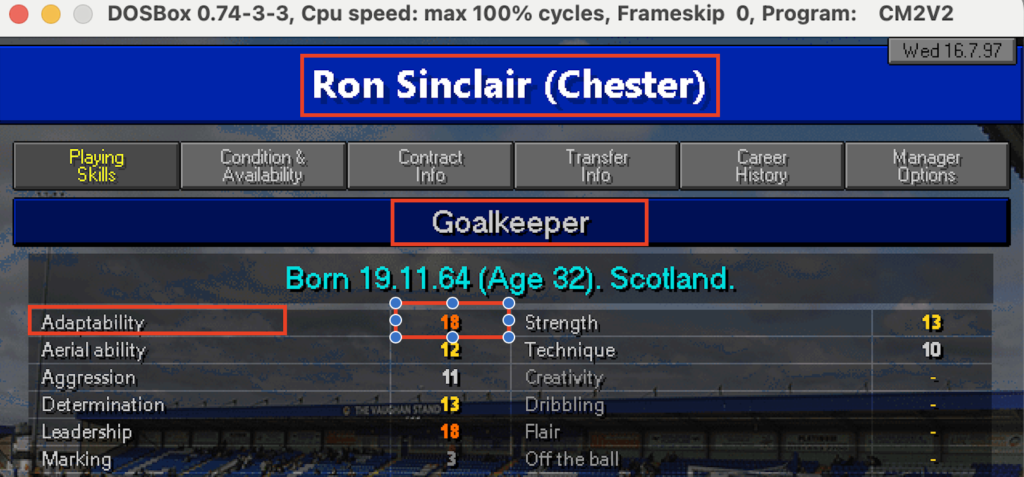
In rosso alcuni esempi di dati da estrarre
E’ chiaro che sarebbe ideale trovare un modo per estrarre solo le aeree in rosso. Ci sarà? Chiediamo a ChatGPT 🙂
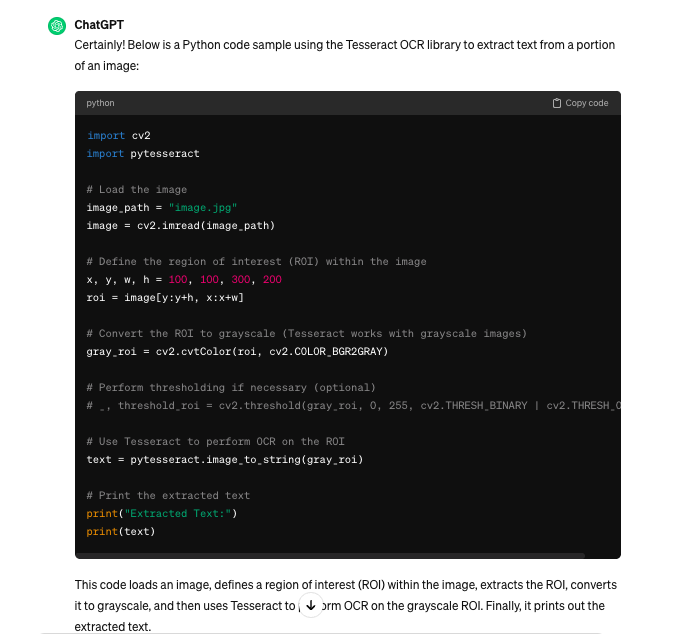
Chiedo a ChatGPT
Notare che ho pure scritto wite invece di write, non volontariamente, è solo un typo, ma vediamo come ci risponde.
Codice Python
Bene, ChatGPT ci espone tutto il codice da utilizzare: viene definita una ROI (region of interest) dell’immagine, viene convertita in scala di grigio e poi infine si estrae il testo così come facevamo anche nel caso precedente. Ok proviamo con un esempio: proviamo ad estrarre il nome del calciatore:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
print(file)
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
x, y, w, h = 110, 140, 1240, 100
#Define ROI
roi = img[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
plt.imshow(gray_roi, cmap='gray')
plt.show()
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(gray_roi)
# Extract relevant information from the data
print(extracted_data)
Come si può notare ho riprodotto fedelmente quanto indicato da ChatGPT, operando qualche accorgimento:
Itero tutti files presenti nella cartella
per ognuno di essi fisso x,y,w,h in modo da centrare esattamente il quadro dove sta il nome
Estraggo il frammento d’immagine con una scala di grigio
utilizzo una libreria per farmi vedere il frammento e capire se è realmente corretto
infine faccio scrivere a schermo il testo
Il risultato è questo:
Risultato acqusizione
Questo è indubbiamente il risultato che mi serve: qui il testo è stato estratto correttamente e può ora essere utilizzato per qualcosa di più strutturato. Purtroppo la parte più ostica è quella di estrarre delle coordinate corrette in cui trovare il testo che ci serve. Andando per tentativi diventa quasi impossibile, quindi googlando ho scoperto che è possibile attraverso la libreria pyplot visualizzare l’immagine selezionata, di conseguenza andando per tentativi possiamo definire pezzo per pezzo le aeree in cui operare l’estrazione effettiva. A questo punto non ci resta che definire pezzo per pezzo dove prelevare i dati che ci servono, estrarli ed in qualche modo convogliarli in un file di ouput che possa essere utilizzabile per aggregare i dati dei vari giocatori.
Nel precedente post al fine di provare ad acquisire e aggregare dati provenienti da schermate di un video gioco anni novanta abbiamo chiesto a ChatGPT di darci una mano nel compito essendo neofiti totali. La scorsa volta ci siamo fermati all’installazione di Python, ora passiamo a Tesseract.
Tesseract
Se proviamo a far girare il codice che ci ha fornito ChatGPT scopriamo che manca un prerequisito che è Tesseract. Ma cos’è esattamente?
Ecco la risposta sempre di ChatGPT
La risposta di ChatGPT
Bene, Tesseract è un OCR ed è utilizzato per estrarre testi dalle immagini: quello che mi serve. E’ Open-Source, supporta il riconoscimento in varie lingue ed è molto accurato se correttamente “allenato” (interessante). Può essere facilmente utilizzato attraverso API e nello sopecifico per sessere tuilizzato in Python necessita della libra “pytesseract”. Direi che è esattamente quello che mi serve. Per installare Tesseract basta un semplice comando con brew [1]
brew install tesseract
Inifine come suggerito da ChatGPT installo anche il wrapper per Python.
pip install pytesseract
A questo punto possiamo cominciare a lavorare sul codice Python per capire come adattarlo e ricondurlo a quelle che sono le mie necessità.
Primo ciclo di codice
Apriamo Visual Studio Code e creiamo un file vuoto Test.py e copiamo il codice suggerito nel post precedente quindi lanciamo l’esecuzione dal menu Run > Start Debugging. Questo è il risultato:
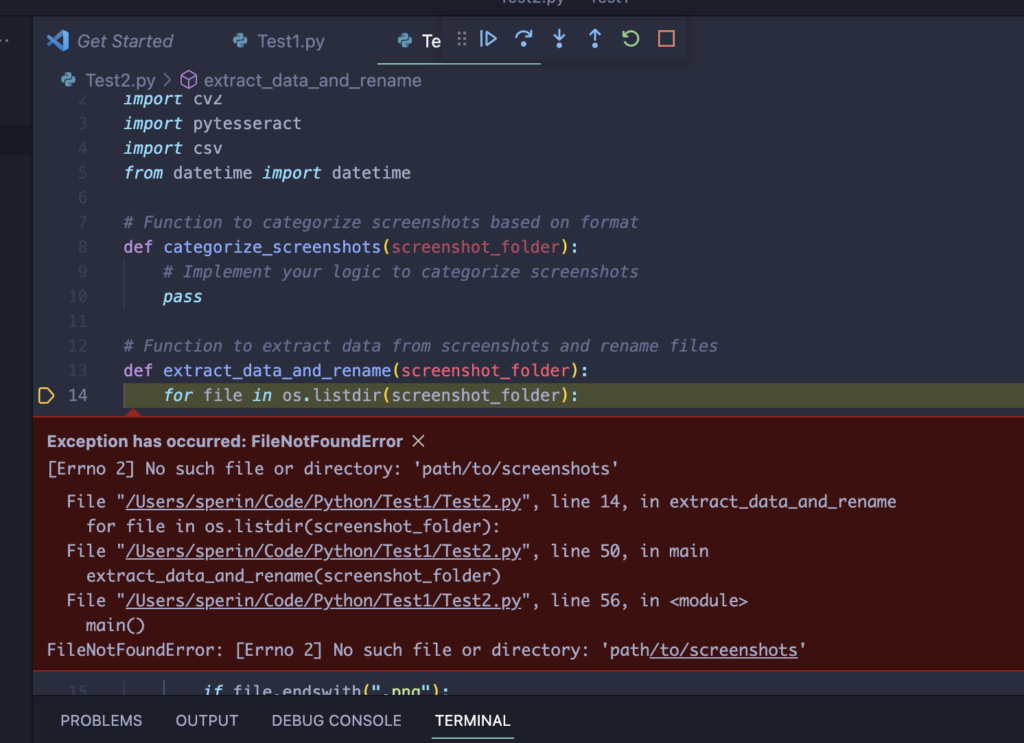
Primo lancio
L’esecuzione va in errore e la modalità debug di Visual Studio Code ci aiuta evidenziando dove sta il problema: certo devo fornire un path corretto dove prelevare gli screenshots. Al netto di questo errore comunque il setup sembra corretto possiamo quindi dedicarci alla parte più divertene: vale a dire scrivere il codice. Anzitutto faccio un po’ di pulizia: rimuovo la parte che fa la categorizzazione perchè al momento non so ancora come poterla implementare e lo stesso faccio con la funzione che scrive il csv. Infine fornisco il path dove ho già preparato alcuni screenshots da cui estrarre il testo che mi serve. Il main dopo questo restyling è molto minimale:
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = ""/Users/xxxx/ScreenCapture""
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)
Infine mi dedico alla funzione principale extract_data_and_rename che chiaramente itera i files nella cartella e tramite pytesseract estrae il testo dell’immagine. Al momento però mi limito a fare un print del dato estratto:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
print(extracted_data)
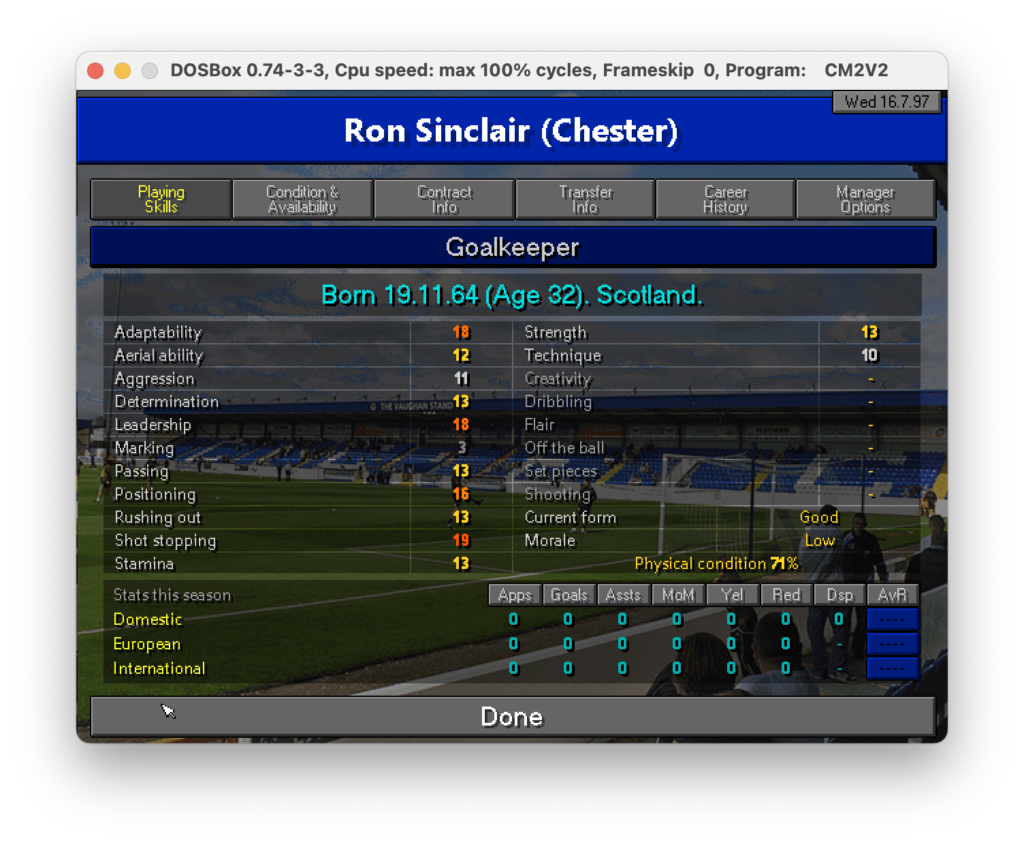
Ok ci siamo se lo lanciamo teoricamente dovrebbe iterare tutti i files png presenti nella cartella e scrivere il contenuto estratto da ognuno di essi a schermo. Per questa prima prova uso una sola immagine:
Immagine sorgente
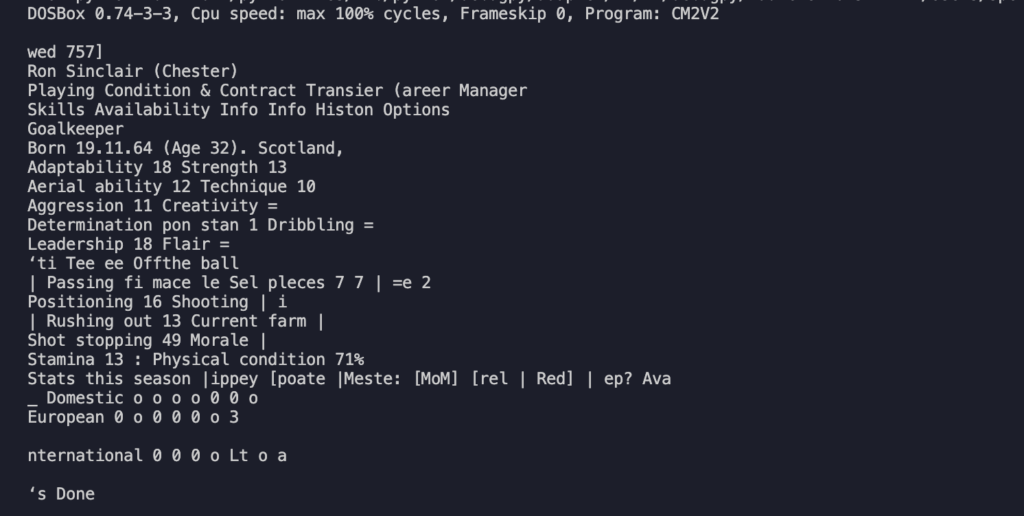
e questo è ciò che il sistema è stato in grado di interpretare:
Testi estratta dallo screenshot
Beh, diciamo che come primo test è già qualcosa però è evidente che alcuni testi sono stati correttamente interpretati mentre altri vanno rivisti. C’è parecchio da lavorare!
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Cookie strettamente necessari
I cookie strettamente necessari dovrebbero essere sempre attivati per poter salvare le tue preferenze per le impostazioni dei cookie.
Se disabiliti questo cookie, non saremo in grado di salvare le tue preferenze. Ciò significa che ogni volta che visiti questo sito web dovrai abilitare o disabilitare nuovamente i cookie.