Da inizio Giugno Edo ha messo fuori dalla sua scala di priorità il ciuccio che, se fino a qualche giorno fa era sostanzialmente un compagno fedele in un tutte le fasi della giornata da oggi non lo è più. E’ successo durante una sessione di Mani, bocca, piedi e ad alcuni dentini che lo ha fortemente destabilizzato, in alcuni momenti anche portandolo a regredire in maniera tosta (non gattonava più, praticamente passava le giornate in maniera passiva). Che fortuna! mi dicono un po’ tutti, non avete dovuto imporlo. Si, verissimo, i miei ad esempio hanno fatto una fatica immane a togliermelo ma c’è un contraltare non banale. Ora si addormenta in maniera più traumatica (non riesce a tranquillizzarsi da solo) e soprattutto la mattina capita molto spesso che si svegli molto presto, le 5:30, le 5:40, le 5:50. Insomma, si fanno passi avanti, parecchi a dire il vero ma c’è sempre un prezzo da pagare. Diciamo poi che il caldo di queste settimane non da una mano, fortuna che abbiamo messo il condizionatore, così almeno anche solo col deumidificatore l’ambiente dove dorme è fresco.
Ormai da inizio Aprile si alza in maniera autonoma e se fino a qualche settimana fa, con il nostro aiuto, tenedogli le manine, faceva pochi passi prima di stancarsi, nelle ultime settimane sembra prenderci molto gusto anche se ancora in termini di equilibrio è molto instabile. Stiamo scaldando i motori dunque, ci avvicianiamo al rilascio della nuova versione con la funzionalità camminata.
Una libreria plug&play per implementare l’autenticazione tramite JWT token in .NET 8.0
Quando si creano delle Web API uno dei temi ricorrenti è come gestire l’autenticazione per consentire un uso autorizzato delle funzionalità esposte. E’ infatti poco vero simile che le delle API vengano esposte in maniera totalmente priva di autorizzazione specie se fanno le classi che CRUD che vanno quindi a persistere dei dati su un qualsivoglia tipo di repository. Premesso che sono molteplici le possibilità di implementazione la mia scelta è caduta sul token JWT [1] uno standard che consente di encriptare alcune informazioni chiave in un formato ben definito.
Nel dettaglio listo quelli che sono per me i requisiti chiave:
Tecnologia: .NET 8.0
Database/Repository: MySQL
Formato Token: JWT
Plug&Play: questa libreria potrà essere aggiunta ad una qualsiasi WebAPI .NET e con pochi step di configurazione gestirne l’authenticazione
Nella creazione di questa libreria mi sono basato su questo link [2] che spiega molto bene tutti gli steps principali. Su Github [3] trovate il progetto da cui potete scaricare il codice sorgente.
Il Modello
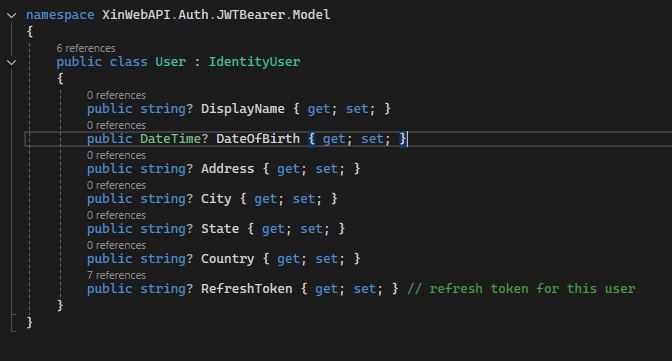
Per questa implementazione sfruttiamo il modulo ASPNETCore.Identity che fornisce già una base sui cui lavorare. Nella fattispecie creiamo una classe User che erediti da IdentityUser estendendone alcune property.
User Model
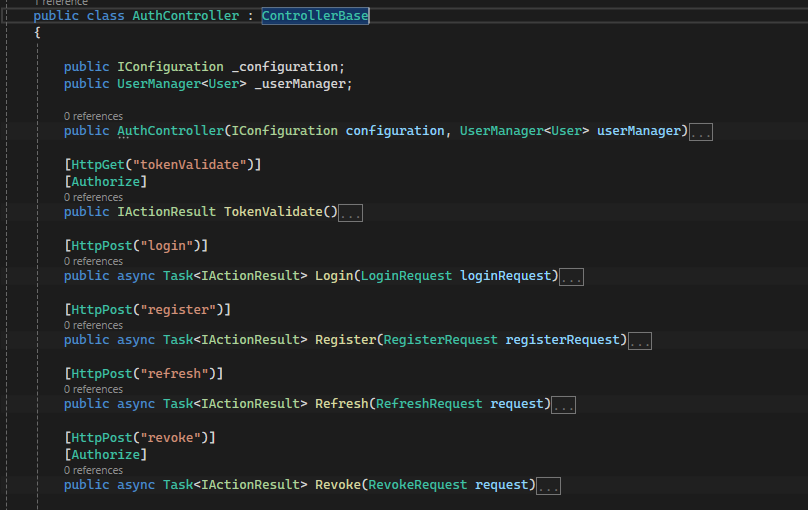
A questo punto implementiamo l’AuthController che sfrutterà parte delle funzionalità fornite dallo User Manager della stessa libreria di cui sopra.
AuthController
Non mi dilungo troppo perchè nell’articolo da cui ho preso spunto è tutto spiegato per filo e per segno ma in sostanza i metodi implementati servono a gestire la creazione del JWT token e il relativo refresh. ATTENZIONE: il refresh token è memorizzato nel campo relativo dello User. Il che significa che quando il token scade chi consuma il servizio può richiedere un nuovo token ricorrendo a questo refresh token senza una nuova authenticazione.
Il Service
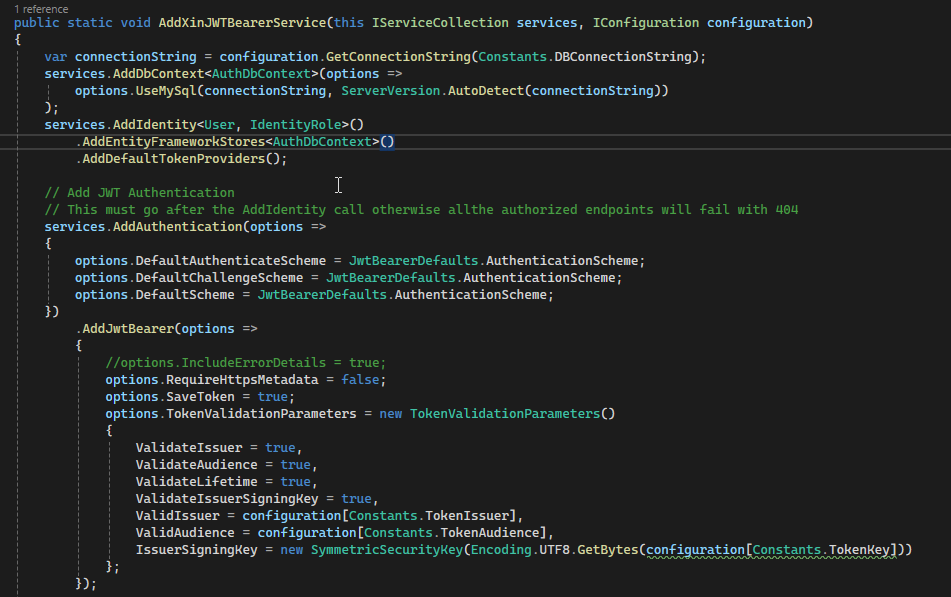
Ma come avviene la validazione del Token? Sempre sfruttando la libreria ASPNETCore.Identity andiamo a creare un extension di Service Collection che effettuerà la configurazione del token impostando:
il repository: in questo caso MySQL
lo schema di autenticazione: in questo caso JwtBearer
Service Extension
Come si può notare, alcuni parametri vengono prelevati dal configuraiton e vengono dunque dall’app che sta effettivamente utilizzando la libreria.
Come utilizzarla?
L’utilizzo è molto semplice e verte su questi punti:
Aggiungere la libreria al progetto
Configurare AppSettings includendo:
La connectionstring per il DB MySQL
La sezione del token con tutti i parametri relativi
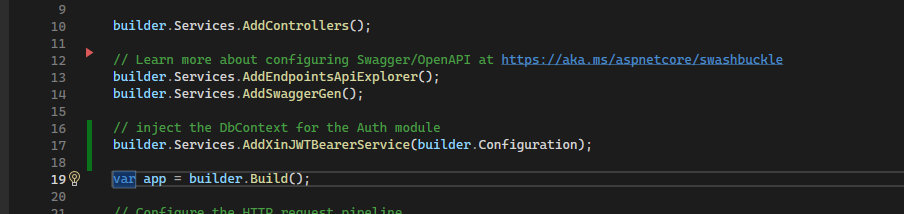
Aggiungere la chiamata al service nel program.cs
Program.cs
Questo dovrebbe essere tutto. Tenete conto che l’implementazione del repository si basa su EntityFramework il che significa che un semplice cambio di API e qualche linea di codice si può estendere facilmente a tutti i repository che abbiano un EntityFramework library che li gestisca.
E’ già trascorso un anno, potrei dire volato in maniera più che letterale, da quando lo scorso anno, il 23 Aprile, Edo è entrato nelle nostre vite cambiandole radicalmente. Non voglio perdermi troppo in analisi su come era il prima e sul cosa sia cambiato poi: mi era ben chiaro che un cambiamento simile avrebbe stravolto tutto. E’ più facile raccontare le notti insonni (ben poche a dire il vero), i pannolini, le pappe, i pianti (anche questi pochissimi) … è molto più complesso invece descrivere ciò che di bello ci sta dietro e che, purtroppo devo essere retorico, solo chi ha realmente provato può capire fino infondo.
Non si è mai pronti per fare il genitore, almeno con i primo figlio, e si deve fare un grande sforzo per accettare i propri limiti e conviverci facendo sempre del proprio meglio senza però farne una ragione di frustrazione. Ricorderò sempre la sensazione strana e anche un po’ preoccupata di non essere più in due in casa ma, di avere un altro esserino con noi che respirava la nostra stessa aria e che dipendeva in tutto e pertutto dalle nostre attenzioni così come dalle nostre mancanze. In certi momenti può essere davvero paralizzante il timore di non fare la cosa giusta, di semplicemente essere inadeguato ma questa può essere la sensazione di un momento non certo uno stato finale. Ho riscoperto in questi mesi che cosa sia l’istinto: un qualcosa che la nostra società evoluta cerca scientemente di governare e incanalare in comportamenti che siano accettabili dal vivere comune e dal comune buon senso. L’irrazionalità che sta dietro all’istinto nelle persone adulte è inevitabilemente relegata ad alcune aree molto ben circoscritte. La presenza di un neonato azzera quasi completamente queste barriere anche perchè: vai a spiegargliele… E’ questo apre davvero un orizzonte completamente diverso, ti porta a doverti mettere in gioco completamente, non solo il tuo tempo libero ma in tutti gli aspetti della vita quotidiana. E’ una riscoperta straniante ma assolutamente affascianante. Osservare mentre tuo figlio smangiucchia un biscotto senza farsi prendere dal panico ogni volta che sembra sul punto di vomitarlo o strangolarsi richiede tanto istinto, tanta serenità, che spesso non sono così semplici da concepire.
Ma torniamo al lato migliore: quanto è bello tenere tuo figlio in braccio? Quanto è bello tenergli la manina mentre prova ad alzarsi oppure quando indica qualcosa di non meglio identificabile? Quanto riempie il cuore il suo sorriso sdentato e quello sguardo candido? Spesso alla sera si è stanchi e si riesce a malapena a trascinarsi verso il letto e vederlo andare a mille tra un pupazzo, una pallina o una macchinina è in un certo senso rigenerante. Avere un bambino, specie per chi non è giovanissimo come me, ti fa guardare al futuro con speranza, con gioia, con attesa, con stupore. Ti allunga la vita accorciandoti le giornate. E’ un miracolo, nel vero e proprio senso del termine.
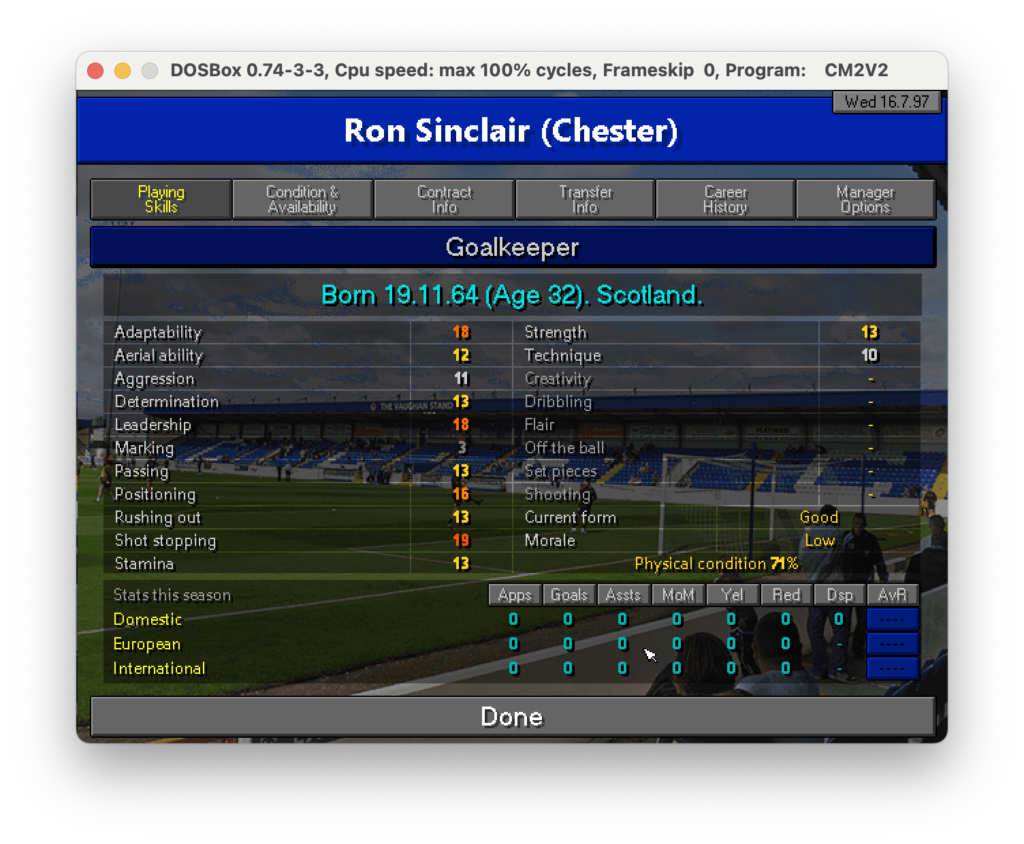
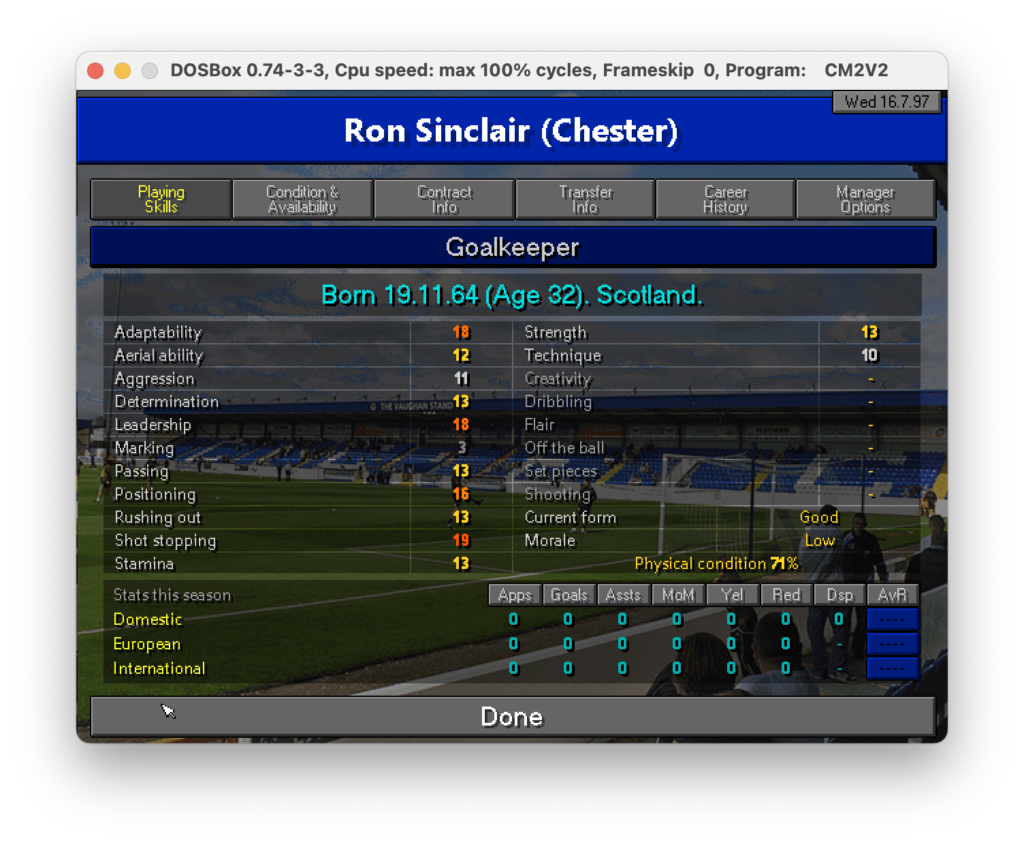
Nell’ultimo post di questa serie abbiamo scoperto come estrarre testo da specifiche parti di un’immagine. Ora, per proseguire nel progetto che ci siamo dati in origine (vedi qui) dobbiamo fare in modo che il dato letto sia correttamente salvato in un file CSV che poi importeremo in seguito. Quindi, ricapitolando: un csv che riporti nella prima colonna il la descrizione del campo come, nome, ruolo e skills e nella seconda colonna il valore di questi campi. Ad esempio nel caso seguente dovremmo partire dall’immagine:
Scheda calciatore
Per ottenere un csv che possa più o meno essere come il seguente:
Esportazione desiderata
Per falro anzitutto creo una funzione Python che mi data un’immagine e le dimensioni in cui è contenuta mi estragga il testo, così evito di dovre riscrivere tutte le volte il codice per estrarle, in più passo come parametro un booleano che, all’occorrenza, mi può anche far vedere l’immagine ritagliata prima di estrarre il testo.
# Function to extract data from a portion of screenshot
def extract_portion_for_csv(x,y,w,h,image,showimg):
roi = image[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
if showimg:
plt.imshow(gray_roi, cmap='gray')
plt.show()
export = pytesseract.image_to_string(gray_roi)
return export
Ora che abbiamo una funzione che estrae il testo da specifiche parti dell’immagine si tratta solo di estrarre ognuna di esse definendo punto per punto dove recuperare il dato. Questa è la parte più noiosa in cui, testo per testo dobbiamo recuperare le coordinate. Per meglio organizzare le cose definisco 2 aree: quella in alto che contiene i dettagli anagrafici del profilo ed una sotto che contiene la parte di skills. Questo frammento estrae la parte anagrafica:
Ad una prima analisi possono sembrare complessi ma in realtà non lo sono: sono semplicemente abbastanza ripetitivi. Per ognuno dei testi che dobbiamo estrarre facciamo in modo di specificare le coordinate e mettiamo tutti i testi all’interno di una matrice così da utilizzarla poi nella scrittura del file csv tramite questo frammento:
def write_to_csv (csv_folder, csv_filename, matrixtowrite):
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerows(matrixtowrite)
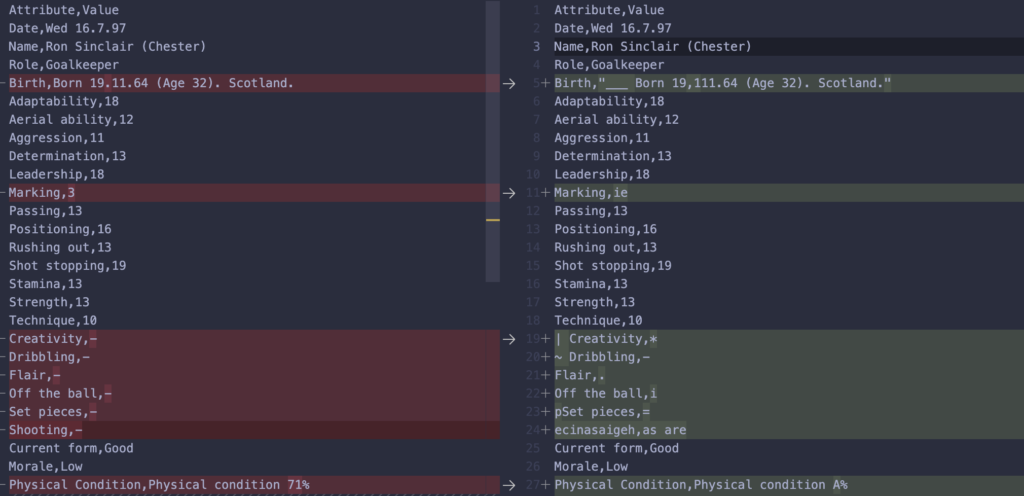
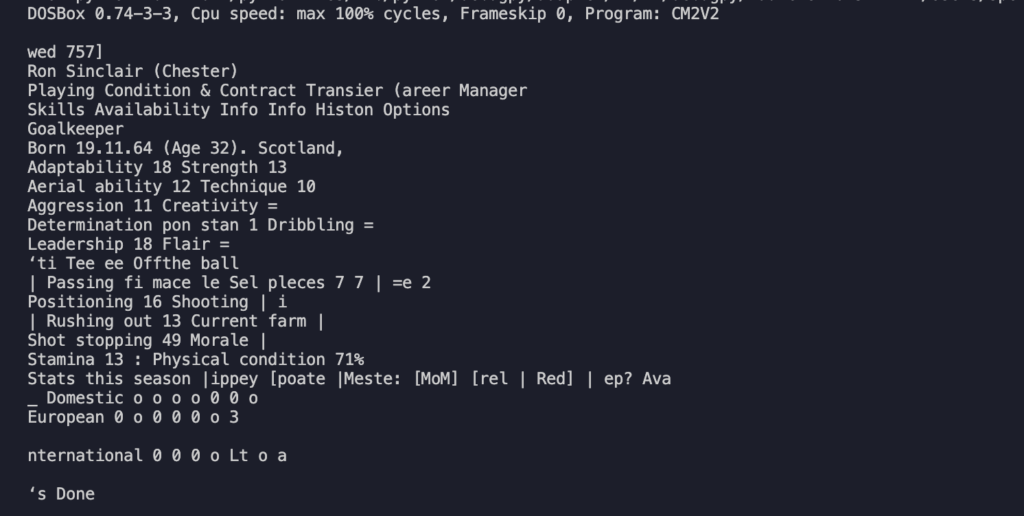
Come si può notare riempiamo una variabile matrix, una matrice che poi utilizzero per scrivere il file stesso. Il file generato contiene l’estrazione completa, confrontandola con la desiderata notiamo delle differenze:
Desiderata a sinistra, risultato dell’estrazione a destra
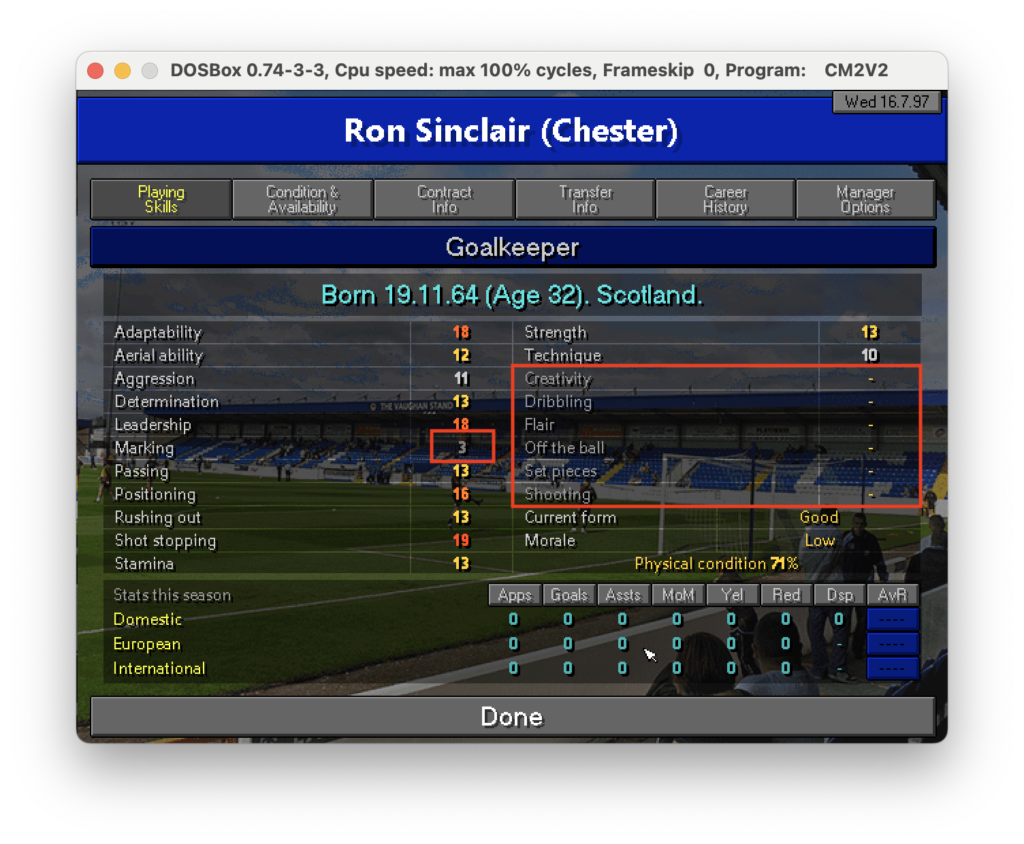
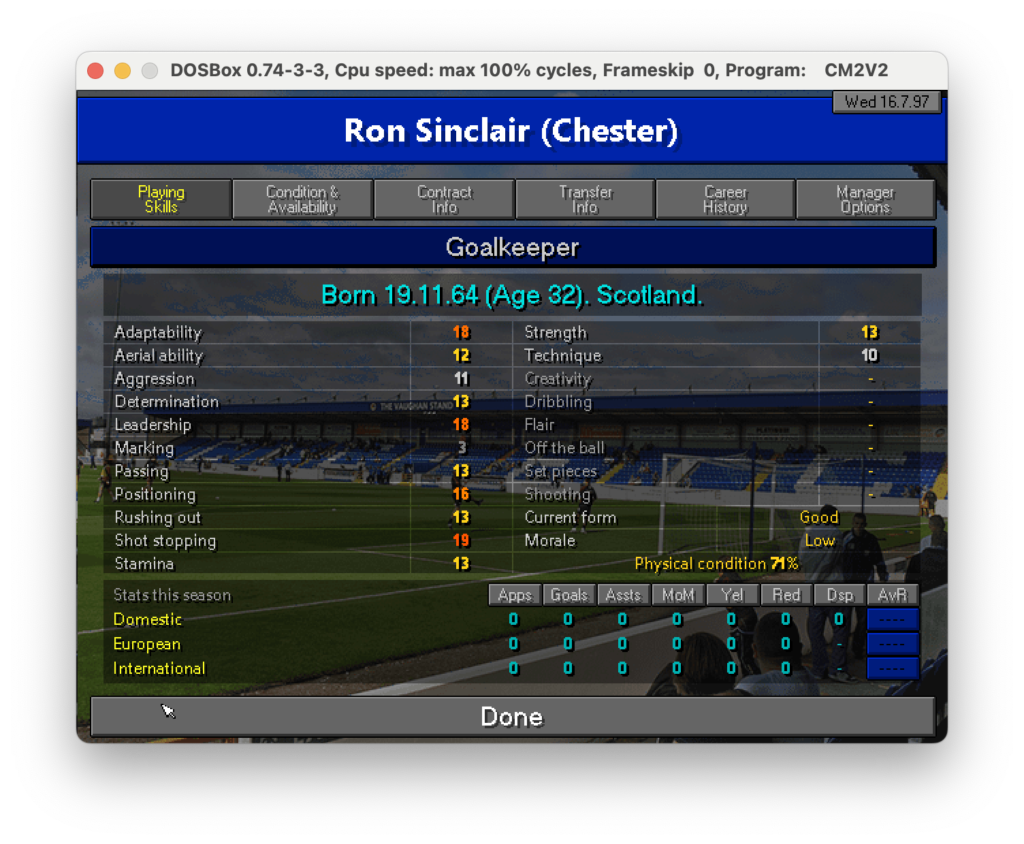
Come si può notare il risultato non è male ma lontano dall’essere perfetto: ci sono molti caratteri speciali che sporcano la lettura come “_”, “*”, “=”. Probabilmente le parti meno riconoscibili sono i trattini “-” e i numeri che hanno un colore del font minore meno pronunciato come quello in Marking 3. Il sistema sembra fare fatica a lavorare dove c’è un contrasto basso. Se guardiamo infatti la figura possiamo notare che tutte le parti che non sono state riconosciute sembrano essere meno evidenti delle altre.
Immagine originale con le parti meno chiare evidenziate in rosso
E’ chiaro che un file così non può essere importato per essere acquisito. L’ideale è capire come migliorare la qualità dell’estrazione, specie per quei caratteri che hanno un basso contrasto. Proviamo a fare una domanda specifica a ChatGPT:
Come posso aumentare l’accuratezza quando il contrasto è basso?
La risposta purtroppo non preannuncia nulla di buono: sembra non sia così semplice . Nel prossimo post analizzeremo le proposte di ChatGPT e proveremo a capire se è possibile migliorare il risultato.
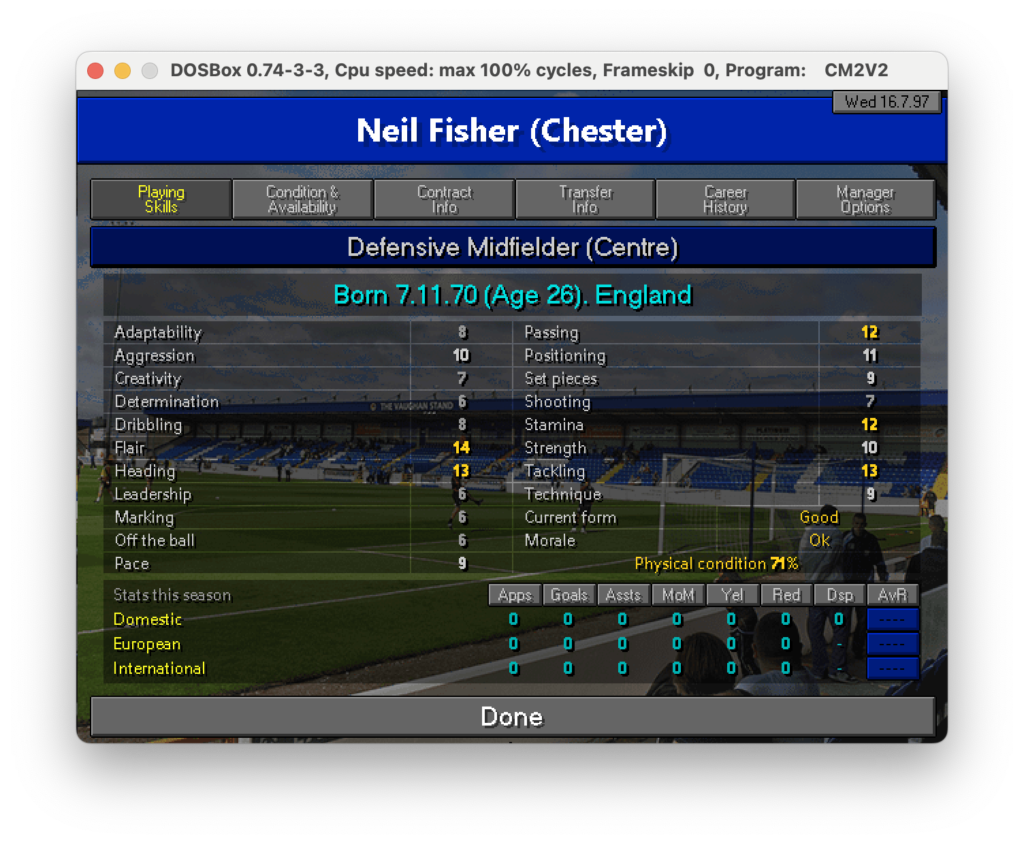
Nello scorso post abbiamo visto come estrarre i testi da una schermata. Purtroppo nel caso analizzato abbiamo molti dati dispersi in vari punti e questo ci ha fornito un estratto difficilmente elaborabile.
Schermata Giocatore
Ciò che gioca a nostro favore in realtà è che il formato del dato è quello per tutte le schermate, ciò che cambierà sarà certamente il nome del calciatore, le info anagrafiche ed i valori delle skills. Fortunatamente la struttura ed il posizionamento sono praticamente identici. In soldoni: sappiamo precisamente dove andare a reperire le informazioni, quindi se ci fosse un modo per restringere il campo potremmo estrarre i dati un po’ alla volta selezionando solo ciò che ci serve.
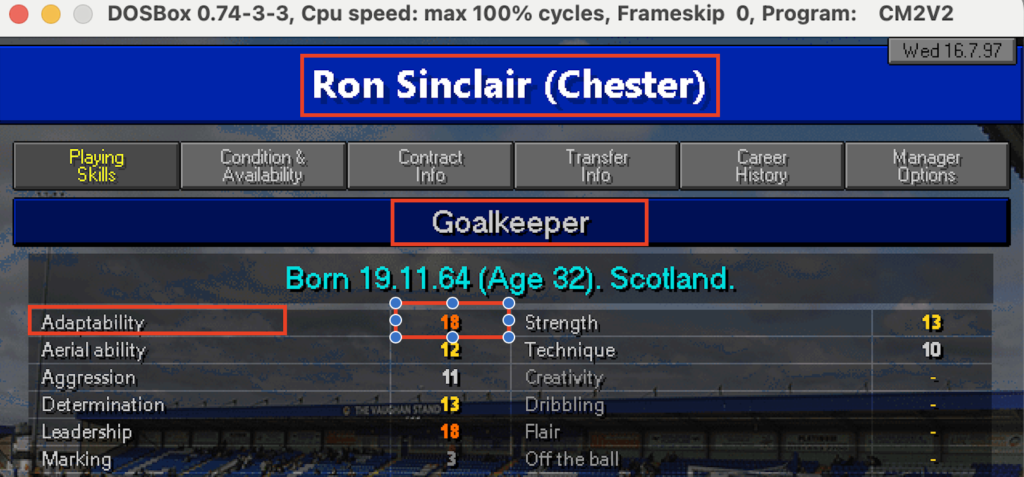
In rosso alcuni esempi di dati da estrarre
E’ chiaro che sarebbe ideale trovare un modo per estrarre solo le aeree in rosso. Ci sarà? Chiediamo a ChatGPT 🙂
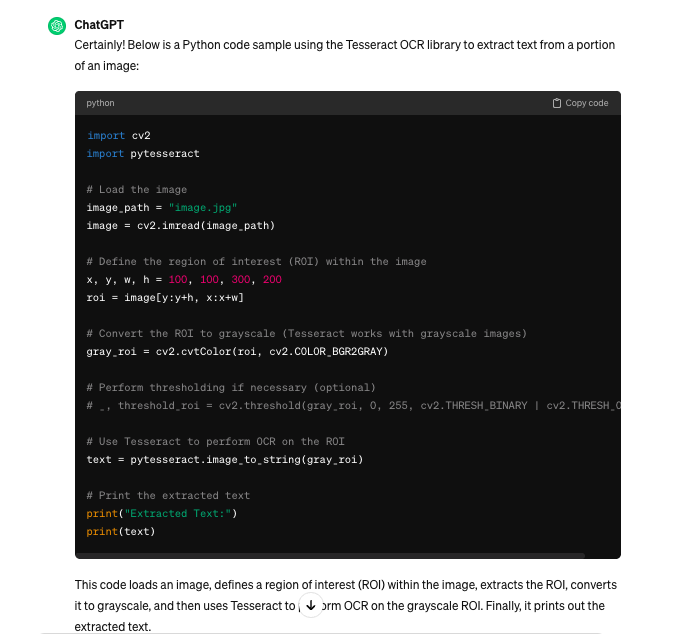
Chiedo a ChatGPT
Notare che ho pure scritto wite invece di write, non volontariamente, è solo un typo, ma vediamo come ci risponde.
Codice Python
Bene, ChatGPT ci espone tutto il codice da utilizzare: viene definita una ROI (region of interest) dell’immagine, viene convertita in scala di grigio e poi infine si estrae il testo così come facevamo anche nel caso precedente. Ok proviamo con un esempio: proviamo ad estrarre il nome del calciatore:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
print(file)
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
x, y, w, h = 110, 140, 1240, 100
#Define ROI
roi = img[y:y+h,x:x+w]
gray_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
plt.imshow(gray_roi, cmap='gray')
plt.show()
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(gray_roi)
# Extract relevant information from the data
print(extracted_data)
Come si può notare ho riprodotto fedelmente quanto indicato da ChatGPT, operando qualche accorgimento:
Itero tutti files presenti nella cartella
per ognuno di essi fisso x,y,w,h in modo da centrare esattamente il quadro dove sta il nome
Estraggo il frammento d’immagine con una scala di grigio
utilizzo una libreria per farmi vedere il frammento e capire se è realmente corretto
infine faccio scrivere a schermo il testo
Il risultato è questo:
Risultato acqusizione
Questo è indubbiamente il risultato che mi serve: qui il testo è stato estratto correttamente e può ora essere utilizzato per qualcosa di più strutturato. Purtroppo la parte più ostica è quella di estrarre delle coordinate corrette in cui trovare il testo che ci serve. Andando per tentativi diventa quasi impossibile, quindi googlando ho scoperto che è possibile attraverso la libreria pyplot visualizzare l’immagine selezionata, di conseguenza andando per tentativi possiamo definire pezzo per pezzo le aeree in cui operare l’estrazione effettiva. A questo punto non ci resta che definire pezzo per pezzo dove prelevare i dati che ci servono, estrarli ed in qualche modo convogliarli in un file di ouput che possa essere utilizzabile per aggregare i dati dei vari giocatori.
Nel precedente post al fine di provare ad acquisire e aggregare dati provenienti da schermate di un video gioco anni novanta abbiamo chiesto a ChatGPT di darci una mano nel compito essendo neofiti totali. La scorsa volta ci siamo fermati all’installazione di Python, ora passiamo a Tesseract.
Tesseract
Se proviamo a far girare il codice che ci ha fornito ChatGPT scopriamo che manca un prerequisito che è Tesseract. Ma cos’è esattamente?
Ecco la risposta sempre di ChatGPT
La risposta di ChatGPT
Bene, Tesseract è un OCR ed è utilizzato per estrarre testi dalle immagini: quello che mi serve. E’ Open-Source, supporta il riconoscimento in varie lingue ed è molto accurato se correttamente “allenato” (interessante). Può essere facilmente utilizzato attraverso API e nello sopecifico per sessere tuilizzato in Python necessita della libra “pytesseract”. Direi che è esattamente quello che mi serve. Per installare Tesseract basta un semplice comando con brew [1]
brew install tesseract
Inifine come suggerito da ChatGPT installo anche il wrapper per Python.
pip install pytesseract
A questo punto possiamo cominciare a lavorare sul codice Python per capire come adattarlo e ricondurlo a quelle che sono le mie necessità.
Primo ciclo di codice
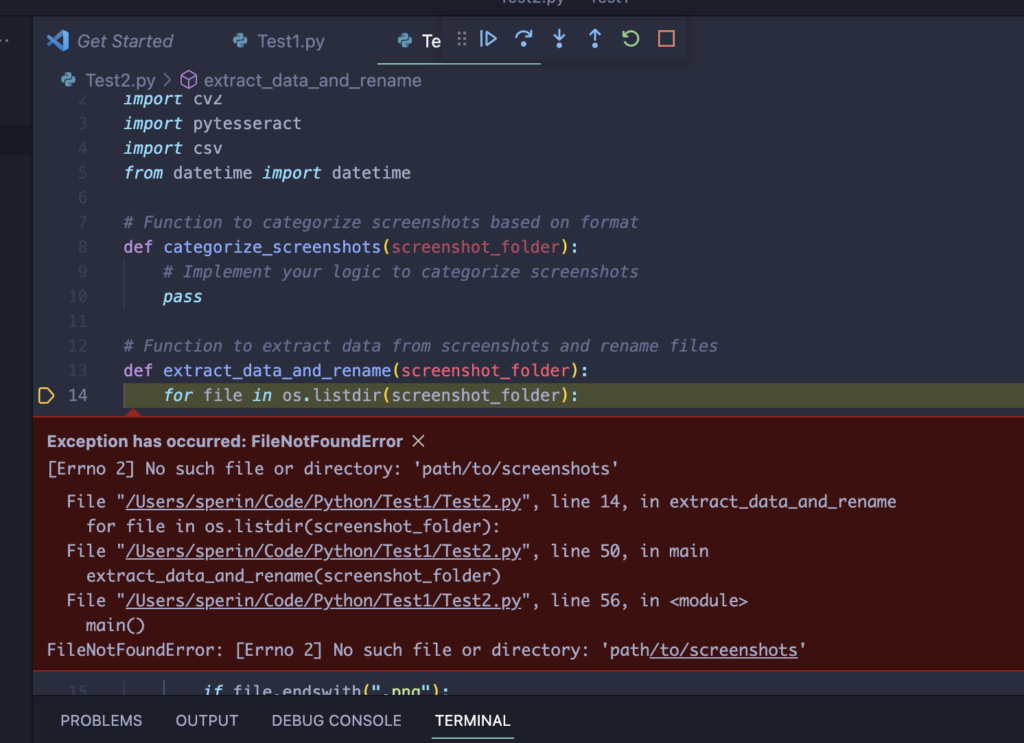
Apriamo Visual Studio Code e creiamo un file vuoto Test.py e copiamo il codice suggerito nel post precedente quindi lanciamo l’esecuzione dal menu Run > Start Debugging. Questo è il risultato:
Primo lancio
L’esecuzione va in errore e la modalità debug di Visual Studio Code ci aiuta evidenziando dove sta il problema: certo devo fornire un path corretto dove prelevare gli screenshots. Al netto di questo errore comunque il setup sembra corretto possiamo quindi dedicarci alla parte più divertene: vale a dire scrivere il codice. Anzitutto faccio un po’ di pulizia: rimuovo la parte che fa la categorizzazione perchè al momento non so ancora come poterla implementare e lo stesso faccio con la funzione che scrive il csv. Infine fornisco il path dove ho già preparato alcuni screenshots da cui estrarre il testo che mi serve. Il main dopo questo restyling è molto minimale:
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = ""/Users/xxxx/ScreenCapture""
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)
Infine mi dedico alla funzione principale extract_data_and_rename che chiaramente itera i files nella cartella e tramite pytesseract estrae il testo dell’immagine. Al momento però mi limito a fare un print del dato estratto:
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
print(extracted_data)
Ok ci siamo se lo lanciamo teoricamente dovrebbe iterare tutti i files png presenti nella cartella e scrivere il contenuto estratto da ognuno di essi a schermo. Per questa prima prova uso una sola immagine:
Immagine sorgente
e questo è ciò che il sistema è stato in grado di interpretare:
Testi estratta dallo screenshot
Beh, diciamo che come primo test è già qualcosa però è evidente che alcuni testi sono stati correttamente interpretati mentre altri vanno rivisti. C’è parecchio da lavorare!
Qualche giorno fa in questo post [1] parlavo dei temi relativi all’AI e le sue differenze con la pura automazione. Come esempio pratico vorrei provare ad acquisire in automatico i dati provenienti da alcune immagini e convogliare queste informazioni in un excel. Dovete sapere che io sono un grande amante dei giochi degli anni ottanta e novanta. E voi direte che centra questo? Uno dei giochi sul quale ho perso letteralmente le notti quando ero poco più che un teenager era Championship Manager (Scudetto nell’edizione italiana). E’ stato il primo gioco a fornire una simulazione di ottimo livello del manager calcistico. Sono passati gli anni, sarà l’età avanzata, sarà del sano romanticismo, ma ancora questo gioco riesce a toccare corde cui i giochi strafighi di oggi difficilmente riescono a sfiorare. Se non lo conoscete vi invito a fare un giro su questo sito [2] dove potete addirittura scaricare il gioco (nella versione 97/98) e con dosbox [3] un simulatore di DOS potete persino giocarci. Ebbene una delle cose che ho sempre desiderato fare è avere uno scarico dei dati di giocatori e partite per poterli incrociare avere delle statistiche da cui possibilmente evincere trends ed informazioni utili a schierare le formazioni migliori.
Una schermata di esempio è quella delle skills di un singolo calciatore in cui ci sono info anagrafiche e capacità tecniche
Scheda calciatore
Nella fattispecie mi piacerebbe quindi avere in un unico excel le skills per colonna e i giocatori per riga magari indicando anche la data in cui questi dati sono stati raccolti con l’idea di poter monitorare un giocatore anche in giorni diversi nel caso le sue skills migliorino o peggiorino. Detto questo non ho la minima idea di come procedere, quindi chiedo a ChatGPT se mi può dare una mano:
Definizione del requisito
Chiedo scusa per l’inglese maccheronico, ma penso si capisca abbastanza bene. Ed ecco la risposta:
Prima parte della risposta
Bene, diciamo che già la lista delle attività pone sul tavolo alcuni strumenti come Python, OpenCV… In più mi porta cnhe un esempio di codice Python da utilizzare:
import os
import cv2
import pytesseract
import csv
from datetime import datetime
# Function to categorize screenshots based on format
def categorize_screenshots(screenshot_folder):
# Implement your logic to categorize screenshots
pass
# Function to extract data from screenshots and rename files
def extract_data_and_rename(screenshot_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
# Implement OCR to extract data from the image
extracted_data = pytesseract.image_to_string(img)
# Extract relevant information from the data
# Rename the file using extracted data and current date
new_filename = f"{extracted_data}_{datetime.now().strftime('%Y-%m-%d')}.png"
os.rename(img_path, os.path.join(screenshot_folder, new_filename))
# Function to fill CSV files with data from screenshots
def fill_csv_files(screenshot_folder, csv_folder):
for file in os.listdir(screenshot_folder):
if file.endswith(".png"):
img_path = os.path.join(screenshot_folder, file)
img = cv2.imread(img_path)
extracted_data = pytesseract.image_to_string(img)
# Write extracted data to CSV file
csv_filename = file.replace(".png", ".csv")
with open(os.path.join(csv_folder, csv_filename), "w", newline="") as csvfile:
csv_writer = csv.writer(csvfile)
# Write data to CSV file
csv_writer.writerow(extracted_data.split("\n"))
# Main function to execute the workflow
def main():
# Path to the folder containing screenshots
screenshot_folder = "path/to/screenshots"
# Path to the folder where CSV files will be stored
csv_folder = "path/to/csv_files"
# Categorize screenshots
categorize_screenshots(screenshot_folder)
# Extract data from screenshots and rename files
extract_data_and_rename(screenshot_folder)
# Fill CSV files with data from screenshots
fill_csv_files(screenshot_folder, csv_folder)
if __name__ == "__main__":
main()
Fantastico: non avevo idea da dove cominicare e ChatGPT mi ha dato delle indicazioni preziose per cominiciare ad approfondire i temi.
Python
Non conosco questo linguaggio se non per sentito dire: non ho mai scritto mezza riga di codice, ma mi sembra di poter dire, dall’esempio che riporta ChatGPT, non sia poi così complesso. Leggendo su Wikipedia [4] tra l’altro scopro che deve il nome ai Monthy Python, già questa la dice lunga. Installarlo non è complesso basta seguire gli step indicati nelle varie guide online (tipo questa [5]). Anzitutto verifico che non sia già presente con questo comando a terminale:
python --version
Nel mio caso il risultato è quello che vedete (io ho installato la versione 3)
Bash
Nel caso non lo abbiate installato potete seguire la guida utilizzando brew
brew install python
Ora che Python è finalmente installato possiamo aprire Visual Studio code e utilizzando il codice che ChatGPT ci ha fornito creiamo un file .py di test da eseguire.
Nel prossimo post vedremo le librerie da utilizzare in Python così come ce le ha suggerite ChatGPT.
Breve digressione tra le principali differenze che occorrono tra una un’intelligenza artificiale e ciò che è una semplice automazione
Negli ultimi mesi il termine “Intelligenza artificiale” è entrato un po’ ovunque nelle agende politiche e sociali dopo che con ChatGPT si sono materializzati degli utilizzi reali di questo tipo di tecnologia. Come sempre la prima reazione è stata di disgusto, rifiuto, aberrazione: la più classica delle accezioni è stata “perderemo un sacco di posti di lavoro” ma non sono mancate le estremizzazioni come “tra non molto le macchine prenderanno il sopravvento” aka moriremo tutti. Non sono uno psicologo ma non ci voleva un genio per prevedere una reazione simile che, si può tranquillamente a mio avviso, derubricare come una declinazione della più generale resistenza al cambiamento. Naturalmente c’è anche ha cominciato a sfruttarne le positività: da quelli che si sono fatti scrivere le ricerche a scuola a chi ci ha scritto pure dei libri a “quattro mani”. Un fatto è che dai tempi di Asimov e delle sue leggi della robotica l’AI non è più solo fantascenza ma sta divenendo realtà.
1. Un robot non può recar danno a un essere umano né può permettere che, a causa del suo mancato intervento, un essere umano riceva danno. 2. Un robot deve obbedire agli ordini impartiti dagli esseri umani, purché tali ordini non vadano in contrasto alla Prima Legge. 3. Un robot deve proteggere la propria esistenza, purché la salvaguardia di essa non contrasti con la Prima o con la Seconda Legge.
Isaac Asimov – I Robot
Fatta questa premessa, una cosa che fatico sempre molto a differenziare è ciò che è relamente una AI da ciò che è una semplice automazione. E quindi mi sono detto chiediamolo a ChatGPT.
Chiediamo a Chat GPT
Ecco cosa dice in particolare come spiega le differenze l’AI stessa:
Automazione Classica:
L’automazione classica coinvolge la programmazione di regole e procedure fisse per eseguire compiti specifici.
Le attività di automazione classica sono basate su algoritmi e logica predeterminata, senza la capacità di apprendimento o adattamento.
Le azioni da eseguire e le condizioni per eseguirle sono esplicitamente definite dal programmatore.
L’automazione classica è efficace per compiti ripetitivi e ben definiti, ma può mancare di flessibilità per gestire situazioni impreviste o complesse.
Intelligenza Artificiale:
L’intelligenza artificiale è in grado di apprendere dai dati e adattarsi all’ambiente senza essere esplicitamente programmati per compiere determinate azioni.
Gli algoritmi di intelligenza artificiale possono analizzare grandi quantità di dati per rilevare modelli e tendenze, e utilizzare queste informazioni per prendere decisioni o eseguire azioni.
Le IA possono essere addestrate su una varietà di compiti e possono migliorare le loro prestazioni nel tempo attraverso l’apprendimento continuo.
Le IA possono affrontare compiti più complessi e ambigui rispetto all’automazione classica, poiché sono in grado di interpretare e comprendere dati non strutturati o situazioni in evoluzione.
Tutto abbastanza condivisibile e chiaro almeno nella teoria. Mi sorge comunque il dubbio che non è raro che si spacci l’una per l’altra ammesso che poi sia effettivamente sbagliato provare a separarle. Di certo si tende a volte, nelle discussioni da bar ma non solo a dare dell’intelligenza anche a qualcosa che d’intelligenza effettivamente non ne ha. Una macchina può essere bravissa ad eseguire un’automazione: sempre le stesse azioni per cui è programmata e sempre nello stesso modo (probabilmente molot preciso), senza però fare mai un salto che la porti a mettere in discussione quanto fatto finora e migliorarlo. Un buon esercizio potrebbe essere quello di provare a trovare un applicazione pratica in cui scendere nei dettagli e provarne le differenze.
Per component (componente) normalmente si fa riferimento a qualcosa che può essere utilizzato/riutilizzato in diversi contesti normalmente in associazionne con altri componenti. Nel contesto di React.js i component sono oggetti che ritornano sostanzialmente del HTML e sono codificati in files .js. Sono normalmente messi in una cartella “components” nel folder src. Nel caso che vedete sotto andiamo a creare un component Employee e lo posizionamo in quel folder. Se vi interessa approfondire la modalità con cui si linkano le funzionalità tra diversi file js vi rimando a questo post [1].
Cartella components
A questo punto “disegnamo” html direttamente nel componente. Si, in soldoni l’idea è che il componente ritorni il frammento dell’HTML che poi verrà renderizzato da chi il componente lo richiama.
function Employee(){
return <h3>Here is an employe</h3>;
}
export default Employee;
Nell’esempio disegneremo un titolo h3 e lo incorporeremo nella App.js
Come potete notare è fondamentale che la function nel return ritorni un frammento di HTML che sia totalmente contenuto in un unico tag. Questo deve succedere sempre a partire da App.js. All’interno della function e prima del return si possono utilizzare tutti i comandi classici javascript ed implementare logiche, anche complesse. Immaginiamo che per qualche ragione si debbano visualizzare dei tag o delle info piuttosto che altre, in base a delle logiche definite. Una possibilità potrebbe essere quella di creare una variabile ed in base al suo valore decidere cosa renderizzare a schermo.
E’ possibile infatti utilizzare delle variabili all’interno del jsx che viene ritornato dal componente stesso e per farlo basta utilizzare le parentesi graffe {}.
Nell’esempio riportato sopra si usa un’operatore ternario per verificare la variabile e ritornare il frammento che serve in base all’esito di quella verifica. Importante è che l’output sia sempre contentuto in un tag (anche quello vuoto) come nell’esempio. Si possono aggiungere più frammenti {} anche uno di seguito all’altro ma non vanno innestati. Importante: all’interno di questi frammenti si utilizza la sintassi javascript.
E’ bene infine ribadire che un component non è necessario che sappia nulla del contesto in cui è utilizzato perchè deve potenzialmente essere in grado di esistere così com’è. E’ solo chi utilizza che deve conoscere come funziona e come utilizzarlo correttamente.
Lavorando con diversi javascripts files nell’intenzione di separare quanto più possibile il codice e comunque riuscire a sfruttare funzionalità contenute in alcuni files in altri files è molto utile capire come funzionano Import ed Export.
La keyword export serve proprio a rendere disponibile all’esterno di un file una parte di codice definita nel file stesso. Ci sono due modalità con cui farlo: l’export e l’export default.
Export Default: è normalmente utilizzato quando si vuole condivider una specifica parte di codice all’esternoe le keywords da apporre sono export default
// 📂 math.js
const add = (a, b) => a + b;
export default add;
// 📂 main.js
import myAddFunction from './math.js';
const result = myAddFunction(5, 10); // This will call the add function from math.js and store the result in the 'result' variable.
Nell’esempio vediamo come la funziona add esportata nel primo file possa essere utilizza semplicemente importando il file stesso nel file che la vuole utilizzare.
Export: questa modalità è utile quando si vogliono esportare più pezzi di codice dallo stesso file ed in questo caso la keyword da utilizzare sarà solo export
// 📂 math.js
export function add(a, b) {
return a + b;
}
export function subtract(a, b) {
return a - b;
}
// 📂 main.js
import { add, subtract } from './math.js';
const result1 = add(5, 3); // result1 will be 8
const result2 = subtract(10, 4); // result2 will be 6
Import: è invece la keyword che serve ad importare le funzionalità esposte dai files esterni tramite le export e renderle fruibili al contesto del file corrente.
Riassiumiamo qui sotto le prinicpali caratteristiche di entrambi:
Con l’export semplice quando usiamo l’import dobbiamo esplicitamente definire thra parentesi graffe {} quali sono le funzionalità che vogliamo utilizzare e dobbiamo anche fare uso del nome esatto esposto. Con l’export default questo non serve.
All’interno di un file ci possono essere molteplici export ma solo un export default
export e export default possono essere utilizzati all’interno dello stesso file
Per chi volesse approfondire vi lascio un link [1] da cui ho tratto questi spunti.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Cookie strettamente necessari
I cookie strettamente necessari dovrebbero essere sempre attivati per poter salvare le tue preferenze per le impostazioni dei cookie.
Se disabiliti questo cookie, non saremo in grado di salvare le tue preferenze. Ciò significa che ogni volta che visiti questo sito web dovrai abilitare o disabilitare nuovamente i cookie.