Lavorando con diversi javascripts files nell’intenzione di separare quanto più possibile il codice e comunque riuscire a sfruttare funzionalità contenute in alcuni files in altri files è molto utile capire come funzionano Import ed Export.
La keyword export serve proprio a rendere disponibile all’esterno di un file una parte di codice definita nel file stesso. Ci sono due modalità con cui farlo: l’export e l’export default.
Export Default: è normalmente utilizzato quando si vuole condivider una specifica parte di codice all’esternoe le keywords da apporre sono export default
// 📂 math.js
const add = (a, b) => a + b;
export default add;
// 📂 main.js
import myAddFunction from './math.js';
const result = myAddFunction(5, 10); // This will call the add function from math.js and store the result in the 'result' variable.
Nell’esempio vediamo come la funziona add esportata nel primo file possa essere utilizza semplicemente importando il file stesso nel file che la vuole utilizzare.
Export: questa modalità è utile quando si vogliono esportare più pezzi di codice dallo stesso file ed in questo caso la keyword da utilizzare sarà solo export
// 📂 math.js
export function add(a, b) {
return a + b;
}
export function subtract(a, b) {
return a - b;
}
// 📂 main.js
import { add, subtract } from './math.js';
const result1 = add(5, 3); // result1 will be 8
const result2 = subtract(10, 4); // result2 will be 6
Import: è invece la keyword che serve ad importare le funzionalità esposte dai files esterni tramite le export e renderle fruibili al contesto del file corrente.
Riassiumiamo qui sotto le prinicpali caratteristiche di entrambi:
Con l’export semplice quando usiamo l’import dobbiamo esplicitamente definire thra parentesi graffe {} quali sono le funzionalità che vogliamo utilizzare e dobbiamo anche fare uso del nome esatto esposto. Con l’export default questo non serve.
All’interno di un file ci possono essere molteplici export ma solo un export default
export e export default possono essere utilizzati all’interno dello stesso file
Per chi volesse approfondire vi lascio un link [1] da cui ho tratto questi spunti.
Per chi lavora al codice è importante poter aver repository di codice che consenta principalmente due cose:
La gestione del codice in maniera concorrente: tipicamente più sviluppatori possono aver necessità di lavorare sugli stessi files, senza ostacolarsi e senza che l’uno “distrugga” quanto fa l’altro
La gestione delle versioni: avere la possibilità di tenere più versioni dello stesso file basate sul quando il file stesso è stato “salvato” nel repository consentendo rapidamente di individuare possibile problemi introdotti ad esempio con un cambiamento sull’ultima versione e poter riprisitnare una versione qualsiasi precedentemente salvata.
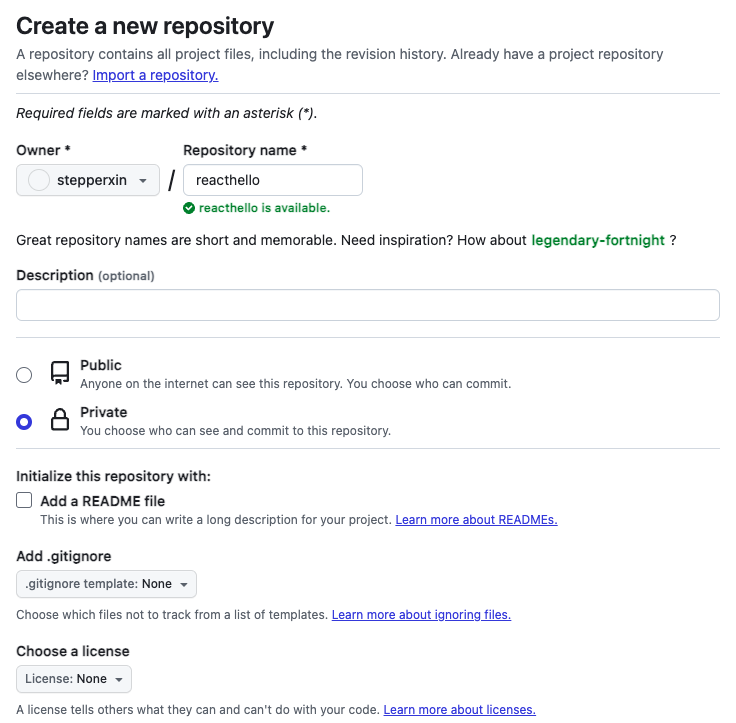
In questo post utilizzeremo come repository GitHub, che è del tutto free e consente agli utenti registrati di avere un repository on cloud sempre disponibile ed anche condivisibile. Assumendo di avere già un account creiamo online un nuovo repository (il nome lo potete scegliere a piacere) evitando di inizializzarlo dato che partiamo da una app react creata localmente (date un’occhiata a questo post [1] se non sapete come farne una).
GitHub – Create Repository
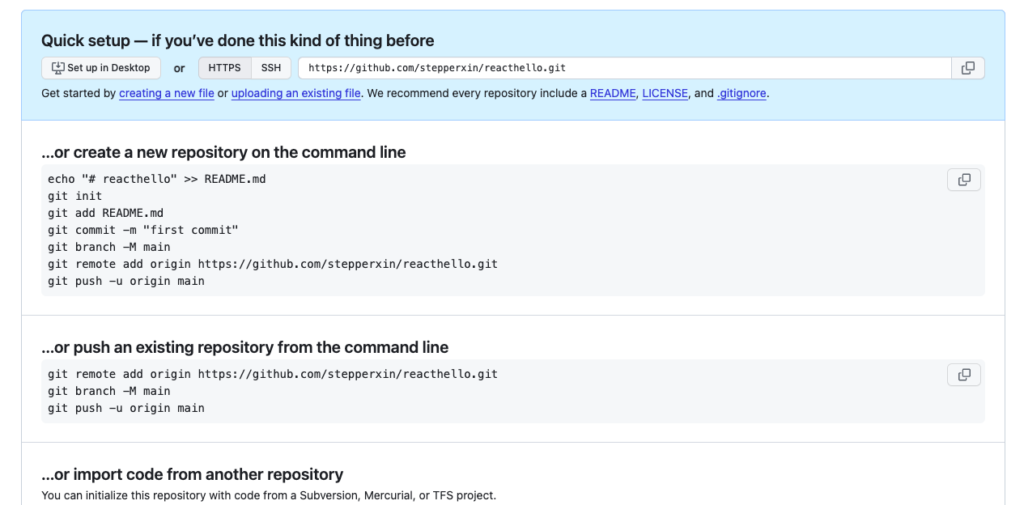
Una volta cliccato su Create Repository viene mostrata una pagina di configurazione in cui sono indicati i comandi da lanciare in console per creare e pushare il codice sul repostory appena creato. Basta copiare, incollare nel terminale e cliccare su invio.
GitHub – Repository Commands
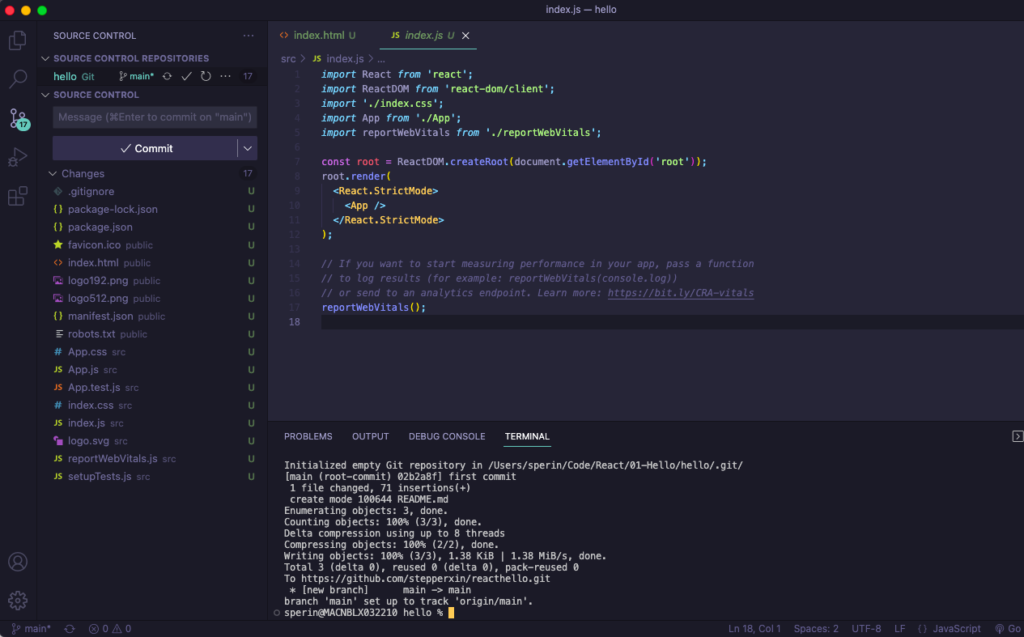
A questo punto nella schermata di Visual Studio Code nel tab del versioning appaiono tutti i files della soluzioni che devono essere aggiunti.
Repository files list
I files hanno ora tutti una U sulla destra ma che significa esattamente?
U (Untracked): sono files aggiunti al progetto ma non ancora commitatti e nemmeno aggiunti all astaging area
M (Modified): un file presente nel repository e modificato
A (Added): un file aggiunto alla staging area
D (deleted): un file tracciato nel repository e cancellato localmente
C (Conflict): un file che ha un conflitto di versione
Quando parliamo di staging area definiamo quei files che vanno a formare un commit e che non sono ancora presenti nel repository.
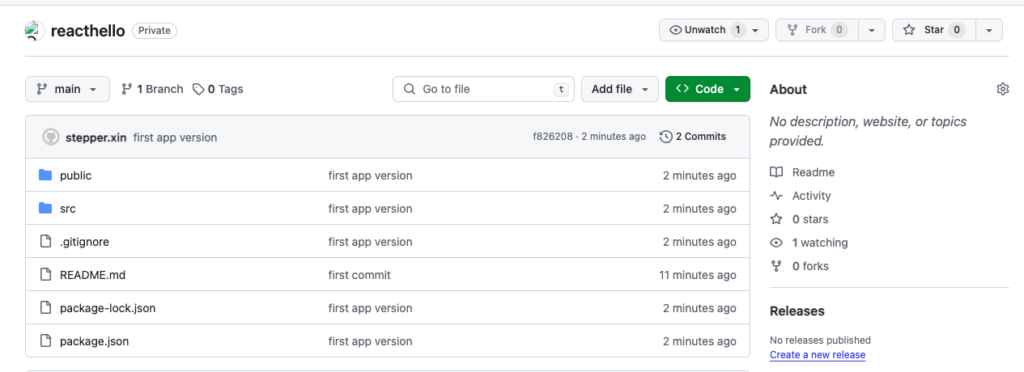
Ora non resta che scrivere un commento nel box e cliccare commit. Quindi premere push per sincronizzare il tutto. Il risultato è che ora in GitHub nel repository indicato ho tutti i files del mio progetto locale.
Respository load in GitHub
Un occhio attento però noterà che non tutti i files che sono presenti nella cartella locale del progetto sono stati importati. Ad esempio build o node_modules non sono presenti. In realtà ciò è corretto ed il perchè è definito all’interno del file .gitignore posso definire quali file ignorare perchè superflui. Nella fattispecie build contiene la pubblicazione del sito mentre node_module ritorna i pacchetti utilizzati per la build.
React è una libreria Javascript tra le più utilizzate nell’implementazione di interfacce web [1]. E’ molto utilizzata per chi lavora con le Sigle Page Application in cui buona sostanza a differenza delle standard web application il DOM viene riscritto per intero ad ogni interazione lasciando al browser l’onere di ridisegnarla in base alla navigazione utente. E’ una modalità che ben si sposa con il concetto di Headless e di architettura composable.
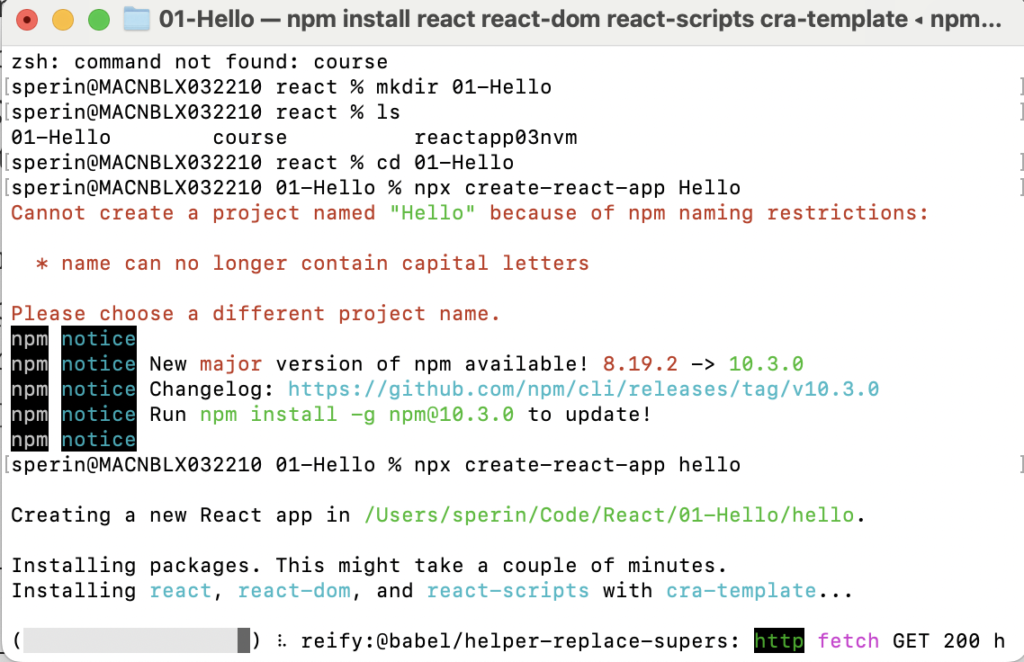
Per prima cosa bisogna installare node.js sulla macchina dove si prevede di sviluppare l’applicazione. A questo punto possiamo utilizzare un comando specifico da terminale per creare l’app: create-react-app. Questo comando lancia la creazione dell’applicazione nella folder corrente del terminale quindi fate attenzione a quando lanciate il comando.
npx create-react-app hello
Crazione della React App
Al termine di un processo che può durare alcuni minuti questo comando genererà la struttura di files che vanno a comporre l’applicazione e che è ben descritta qui [2].
Abbiamo creato il template di app, ora ci serve aprire il tutto in editor di testo dove ci venga facile fare modifiche e lavorare sui files. Ci sono decine di editor ma quello che vi consiglio è Visual Studio Code (lo trovate qui [3]), è free, è leggero ed ha un sacco di estensioni utili. Vale la pena porre attenzione sui due files principali:
Entry Point
Questi files devono essere sempre presenti perchè sono sorgente da cui parte tutto. Index.html in particolare ha in div con id=”root” dal quale parte tutto: è all’interno di questo div che verranno generati di volta in volta i componenti da visualizzare nella pagina.
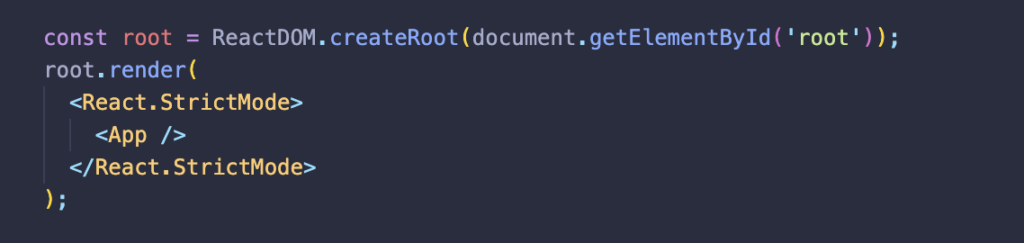
Index.html
Questo compito verrà svolto da index.js che come vedete sotto ricercherà quel did e lo sostituirà con qualcosaltro che la soluzione definisce, in questo caso <App /> che non è nientaltro che tutto ciò che si trova nel file App.js prsente sempre nella cartella src.
index.js
A questo punto per vedere l’app in azione non ci resta che aprire un nuovo Terminal dal menu di Visual Studio Code ed eseguire il comando:
npm start
Ed eccoci quà l’applicazione demo funziona:
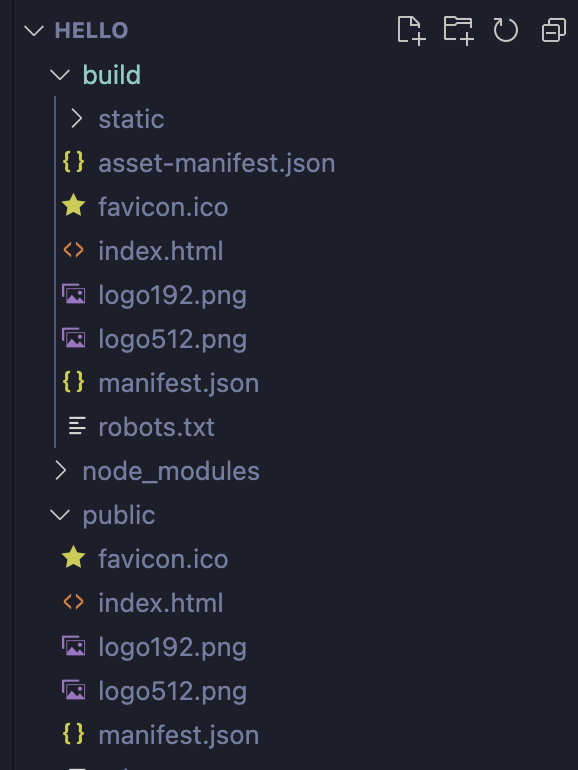
Quando invece dovete pubblicare l’applicazione il comando da utilizzare è leggermente differente: npm run build.
npm run build
Questo genererà una cartella build nella root del progetto.
Build folder
Nella lista dei files se ne trovano due che hanno come nome package.json e package-lock.json. Il nome è molto simile e potrebbe trarre in inganno sul loro significato. Package.json definisce i package e le relative versioni da utilizzare nel progetto. Questo significa che lanciando il comando npm install il sistema in base alle versioni installate sulla macchina definirà quale combinazione di package utilizzare e creerà il file package-lock che a quel punto contiene esattamente tutti i package utilizzati sulla macchina.
Non avevo mai letto nulla di Ballard, così quando questa estate prima delle vacanze mi ero imbattuto in libreria in questo romanzo mi sono ricordato di avere in passato sentito qualche recensione in merito. L’idea in sè è abbastanza semplice e, di questi tempi pure molto gettonata: un futuro in cui le temperature sulla terra cominciano ad alzarsi creando lo scioglimento dei ghiacci e il conseguente innalzamento delle acque con l’inevitabile innondazione delle città e di granparte delle aree normalmente abitate. In questo caso il colpevole è un’attività solare estrema e non l’attività umana ne l’effetto serra dovuto ad altri eventi endogeni come eruzioni vulcaniche o cataclismi di qualche genere. E’ curioso sapere che in passato il nostro pianeta ha già sperimentato temperature simili nel corso della sua storia e, anzi, in alcuni casi ha raggiunto temperature ben peggiori (date un occhio qui per maggiori info [1]).
Protagonista è Robert Kerans, uno scienziato parte di un’unità militare che effettua ricerche nelle aree con temperature estreme (se ho capito bene siamo intorno a Londra) in un paesaggio in cui l’acqua la fa da padrona e le poche persone rimaste a quelle latitudini vivono agli ultimi piani dei palazzi spostandosi dagli uni agli altri attraverso imbarcazioni o aerovelivoli. In questo scenario apocalittico il protagonista si sente visceralmente attirato a sud da qualcosa che non sa spiegarsi e che lo porterà allo scontro con gli altri supersisti. Un qualcosa a metà tra una sorta di richiamo ancestrale parte di un’eredità dei nostri antenati più vecchi ed una sorta di suicidio sull’altare di quel sole senza il quale non possiamo vivere ma che in taluni casi può essere anche letale.
Ballard come tutti i più grandi maestri del genere fantascentifico è bravo nel portarci nella vita delle persone e farci vivere le emozioni ed i drammi che vivono, i dilemmi che le angosciano e le speranze che le tengono in vita senza troppe licenze a technologie futuristiche e creature esotiche. In fondo nella nostra vita di tutti i giorni come in quella di un futuro prossimo, non è tanto importante come viviamo quanto perchè lo facciamo.
Una delle più importanti ragioni percui le WebAPI hanno preso largamente piede negli ultimi anni è la possibilità di disaccoppiare fortemente la parte di rappresentazione da quella del layer dati/applicativo. Questo forte disaccoppiamento necessita però che cambi radicali alle WebAPI non vadano a discapito di chi le consuma: se cambio un API dovrei essere sicuro che una volta cambiata tutto ciò che prima funzionava continui a funzionare nella stessa maniera altrimenti potrei potenzialmente “rompere” delle funzionalità di applicazioni che consumano queste API. La maniera migliore per farla è quella di procedere ad un versionamento delle API, ma prima di farlo occorre capirsi sul quando è necessario creare una nuova versione delle API e quando no. Vi lascio questo link [1] che è ricco di spunti ed è ciò su cui ho basato questo post. Riassumendo le casistiche sarebbero più o meno le seguenti:
Rimuovere o rinominare API o i suoi parametri
Cambiamenti significativi nel comportamento dell’API
Cambiamenti al response contract
Cambiamenti ai codici di errore
Per prima cosa dobbiamo definire le versioni all’interno del Program.cs. In questo caso definiamo anche la version 1 come quella di default.
builder.Services.AddApiVersioning(options =>
{
options.DefaultApiVersion = new ApiVersion(1);
options.ReportApiVersions = true;
options.AssumeDefaultVersionWhenUnspecified = true;
options.ApiVersionReader = ApiVersionReader.Combine(
new UrlSegmentApiVersionReader(),
new HeaderApiVersionReader("X-Api-Version"));
}).AddApiExplorer(options =>
{
options.GroupNameFormat = "'v'V";
options.SubstituteApiVersionInUrl = true;
});
Successivamente occorre decorare il controller con le Versioni supportate e con il conseguente path dinamico basato sulla versione
[ApiVersion(1)]
[ApiVersion(2)]
[Route("api/v{v:apiVersion}/[controller]")]
public class InfoAPIController : ControllerBase
{
A questo punto devono essere decorati appositamente tutti i metodi che hanno più versioni con lo stesso Http Get name ma differente nome C#
Fatto ciò dovremmo quindi essere in grado di usufruire versioni diverse in base al path utilizzato. In realtà, come spiegato per bene nel post sotto, le modalità potrebbero essere differenti ma io opto per un verisoning basato sull’url.
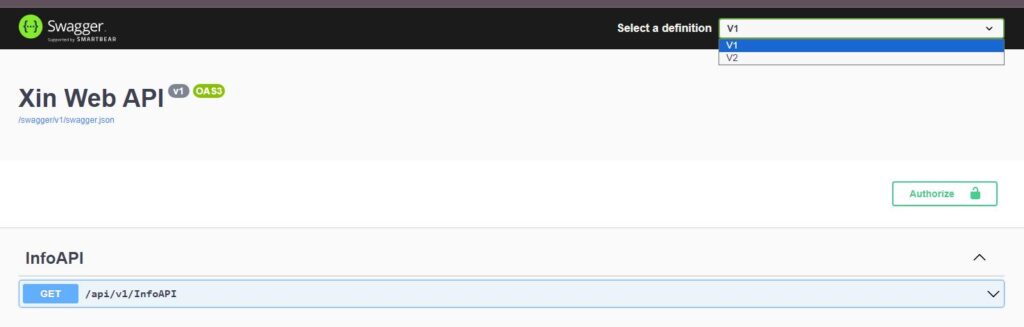
Tutto molto bello ma tutto ciò non basta a visualizzare due differenti versini in Swagger. Per farlo occorrono un altro paio di accortezze che ho scoperto in un altro post [2]. La prima è che vanno configurate le versioni visibili all’interno della configurazione di swagger (nel mio caso sono due):
builder.Services.AddSwaggerGen(options =>
{
options.AddSecurityDefinition("oauth2", new OpenApiSecurityScheme
{
In = ParameterLocation.Header,
Name = "authorization",
Type = SecuritySchemeType.ApiKey
});
options.OperationFilter<SecurityRequirementsOperationFilter>();
options.SwaggerDoc("v1", new OpenApiInfo { Title = "Xin Web API", Version = "v1"});
options.SwaggerDoc("v2", new OpenApiInfo { Title = "Xin Web API", Version = "v2" });
});
Infine nel SwaggerUI vanno registrati i path delle versioni, ma invece di farlo uno ad uno consiglio di utilizzare l’approccio descritto qui [3]
app.UseSwaggerUI(options =>
{
var descriptions = app.DescribeApiVersions();
// Build a swagger endpoint for each discovered API version
foreach (var description in descriptions)
{
var url = $"/swagger/{description.GroupName}/swagger.json";
var name = description.GroupName.ToUpperInvariant();
options.SwaggerEndpoint(url, name);
}
});
Attenzione che i due passi sopra sono fondamentali se volete visualizzare correttamente nella drop down di swagger netrambe le versioni e switchare tra di esse i due punti sopra sono fondamentali.
Quando si lavora su una soluzione è vitale che si abbia la possibilità di differenziare delle configurazioni in base all’ambiente di destinazione “target” della soluzione. L’esempio più semplice è quello delle stringhe di connessione a DB: se si hanno ambienti diversi normalmente serviranno delle stringhe differenti in base al DB. In generale per i progetti asp.net core (e non solo) è possibile gestire tanti settings quanti sono gli ambienti di rilascio, però non è così banale trovare un modo per rendere dinamica questa modalità. Ho travato infatti molta documentazione sul come giocare con le variabili di ambiente [1] che però, nell’ambiente target (una soluzione cloud), non mi è possibile toccare. Dopo varie ore a cercare in rete qualcosa di sensato sono approdato a questa soluzione che vi spiego che in parte trovate anche in questo video.
Definizione di ambienti di rilascio: per prima cosa definiamo quali ambienti deve contemplare la mia soluzione per capire quanti varianti di file di configurazione servono. Nel mio caso sono 4:
Development: la configurazione che utilizzo in Visual Studio quando sviluppo e debuggo
Stage: la configurazione che utilizzo per testare l’applicazione sul’ISS locale della macchina di sviluppo
Sandbox: l’ambiente di preproduzione in cloud
Live: l’ambiente di produzione reale
Per ognuno di questi ambienti mi servirà un file di appsettings dedicato formattato nella seguente maniera: appsettings.{env}.json. Per farlo basta copiare il file appsettings già presente nella soluzione e rinominarlo utilizzando i quattro nomi sopra. Tenete sempre in conto che il primo file ad essere letto è appsettings (quello generico) che poi verrà sovrascritto da quello con il nome dell’ambiente. Questo significa che tutto ciò che chiede di essere specifico per ambiente deve finire in nel file con il nome dell’ambiente stesso.
Caricamento dei settings corretti: in Program.cs carichiamo anzitutto il file appsettings generico all’interno del quale andiamo a creare una configurazione che identifichiamo con Configuration dove scriveremo il target del deploy (uno dei 4 valori sopra). Ed in base a quel valore andiamo a caricare il file dedicato.
var _conf = builder.Configuration.AddJsonFile("appsettings.json", optional: true, false).Build();
string _env = _conf.GetSection("Configuration").Value;
builder.Configuration.AddJsonFile($"appsettings.{_env}.json", optional: true, false);
var app = builder.Build();
In questa maniera basterà identificare nel appsettings generico il target del deploy (volendo anche al volo) all’interno della variabile di configurazione Configuration.
Rilasciare solo i files dell’ambiente: per come fatto sopra e sostanzialmente mostrato anche nel video tutti i files appsettings verranno sempre deliverati in tutti gli ambienti e la cosa non mi mpiace molto perchè si presta ad avere errori se non modifico correttamente il Configuration all’interno dell’appsettings generico. Per ovviare a questo problema genero 3 nuove versioni dal configuration manager: Live, Sandbox e Stage. A questo punto apro il file di progetto in edit ed aggiungo la seguente configurazione che rilascia solo il file corretto in base al target che ho scelto.
In questo modo basterà prima di rilasciare in uno degli ambienti selezionare la tipologia di deploy e verranno solo rilasciati i files di configurazione relativi.
E’ inutile spiegare perchè loggare sia un punto chiave nello sviluppo di un’applicazione. E’ altrettanto inutile dire quanto oggi sia inutile sviluppare un framework custom che lo faccia: ci sono mille plugin che lo fanno (e spesso anche molto bene) per cui c’è davvero l’imbarazzo della scelta. Non tutti però sono semplici da configurare (alcuni sono un vero incubo). La mia scelta dopo vari tentativi è ricaduta su SeriLog. Sul web trovate parecchia documentazione in merito ve ne suggerisco un paio sotto.
Nello specifico queste sono le azioni che ho condotto per installarlo e configurarlo:
Ho inizializzato il Logger all’interno del Program.cs
var logger = new LoggerConfiguration()
.ReadFrom.Configuration(builder.Configuration)
.Enrich.FromLogContext()
.CreateLogger();
builder.Logging.ClearProviders();
builder.Logging.AddSerilog(logger);
Ho aggiunto nel file appsettings.js le configurazioni di scrittura, tra cui il nome del file dov’è posizionato etc…
Con queste semplici azioni il vostro sistema già loggerà in automatico. Qualora vi servisse esplicitamente loggare all’interno dei vostri controller nel caso di un API naturalmente basta utilizzare la solita modalità “iniettiva”.
Questo che segue è un breve riassunto della vita Tuor dalla nascita fino al suo arrivo a Gondolin come narrato nei Racconti Incompiuti di JRR Tolkien. Il redatore del libro, chè è poi Christopher Tolkien (il figlio del grande autore) spiega che questo racconto in origine avrebbe dovuto essere “Tuor e la caduta di Gondolin” ma in realtà si fermerà all’entrata di Tuor a Gondolin.
Tuor: figlio di Huor e Rìan della casa di Hador
Ulmo: Signore delle Acque
Voronwe: Elfo
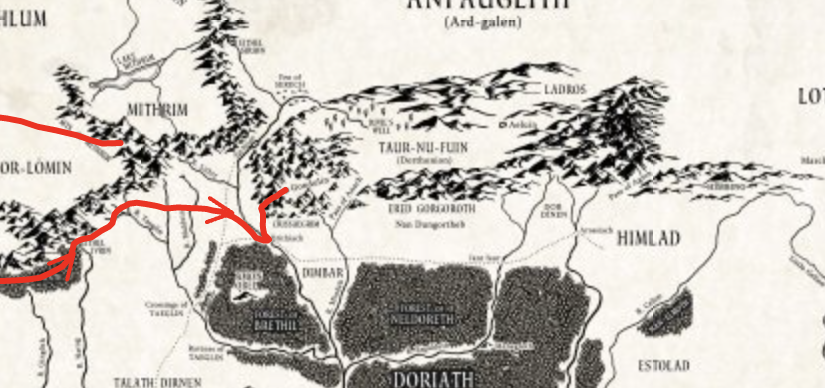
Al termine della Nirnaeth, Huor che al pari del fratello Hurin vi aveva partecipato combattendo al fianco degli Elfi non fa ritorno a casa cadendo sul campo di battaglia. Rìan sua madre, quando ne viene al corrente si lascia morire lasciando il piccolo Huor alle cure degli stessi Elfi. Tuor vi rimarrà fino a 16 anni, e viene a conoscenza del regno celato di Turgon, Re degli elfi, sfuggito a Morgoth nella disfatta della Nirnaeth. Turgon fù coperto nella fuga proprio dal padre Huor e dallo zio Hurin che come già detto pagaro con la propria vita. Da lì a poco gli Orchi attaccheranno ancora gli Elfi riuscendo a disperderli e farlo prigioniero. Tuor però non si darà pervinto e riuscirà con grande abilità a farsi tenere in vita fino a quando alla buona occasione, dopo tre anni, riesce a fuggire e ivi riceve un segno da parte di Ulmo che tramite un ruscello gli indica un passaggio. Il figlio di Huor da lì attraversa tutto il Dorlomin ed il Nevrast fino a giungere al monte Taras a ridosso del grande mare. Tuor entra dunque in Vinyamar l’antica città di pietra eretta dai Noldor. Molto bella è il racconto di quando entra nella sala del trono abbandonata da Turgon ed un segno (un altro) fa si che Tuor rinvenga spada e cotta di maglia lasciate dal re degli Elfi prima di partire: è una sorta di investitura. A questo punto mentre vine attirato sulle rive dalle acque gli appare Ulmo stesso che gli dà il compito di cercare Turgon ed il suo regno celato.
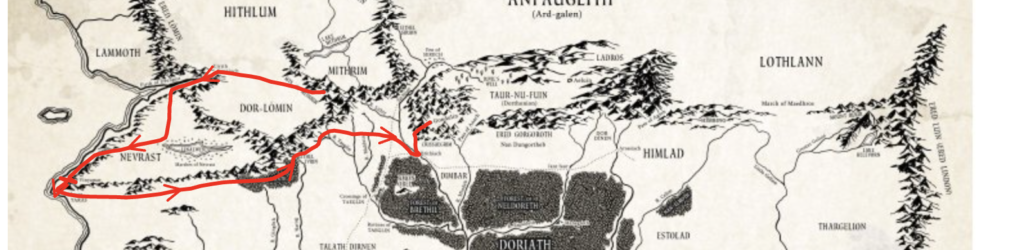
Mappa del percorso di Tuor fino al regno celato di Gondolin [1]
Prima di congedarlo Ulmo gli spiega i dettagli ed il perchè della missione donandogli un manto dal potere di nasconderlo alla luce ed allo sguardo e la promessa di mandargli qualcuno che lo possa condurre nel viaggio a quel posto segreto. Di lì a poco dalle acque emergerà il naufrago Voronwe ultimo superstite di una spedizione di 7 navi elfiche salpate dai Porti di Cìrdan con l’intento di far rotta verso Valinor e chiedere l’intervento dei Valar contro Morgoth. Nessuna di esse era più tornata e la nave di quest’ultimo era stata sferzata dalle tempeste lasciando lui come unico superstite. Tuor spiega della manifestazione di Ulmo e del messaggio che deve recare a Turgon e questo fa vincere l’iniziale ritrosia dell’elfo a mostrare il perscorso al regno celato ad un uomo. Partono quindi alla volta del regno celato. Il cammino è faticoso, tra il freddo gli stenti e i branchi di Orchi che braccano tutto ciò che si muove nelle zone. Tuor e Voronwe nel loro percorso devono mantenere il più stretto segreto, devono essere sicuri di non attirare attenzioni e portarsi dietro cattivi ospiti. Quando arrivano ai Monti Cerchianti, le mura del regime di Turgon, sono ormai allo stremo ma riescono a trovare la gola dove sfociava il Fiume Secco. Infine rinvengono una galleria scavata nella roccia in cui non vi è luce. Lì vengono intercettati da una pattuglia di guardiani Elfi che li identificano e si meravigliano del fatto che un Elfo abbia condotto un uomo per quel percorso, ma consì dell’eccezionalità delle persone che si trovano davanti decidono di scortarli fino da Turgon alchè sia lui a prendere ogni decisione in merito. Di lì vengono quindi condotti per una via angusta passando attraverso sette porte, una più fortificata dell’altra. Il racconto si interrompe dopo l’ultima porta alla visione di Gondolin innevata.
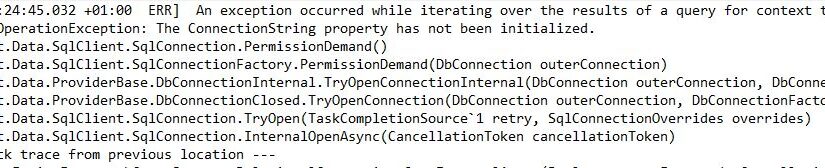
Una delle cose fondamentali che serve per debuggare un applicazione sono i Logs. Avere un sistemi di log efficiente accorcia le tempistiche e favorisce un troubleshooting benfatto. In questo post mostro, brevemente, cosa si deve fare per utilizzare NLog a tal fine. Non voglio essere troppo noioso analizzando tutte le varie casistiche (nel caso vi consiglio questa lettura [1]) ma, voglio arrivare dritto al punto. Quello che a me serve è qualcosa che ad ogni eccezione venga correttamente loggata indipendentemente dal fatto che sia gestita e scriva in un file tutto quello che è successo.
A questo scopo installiamo i seguenti package NuGet:
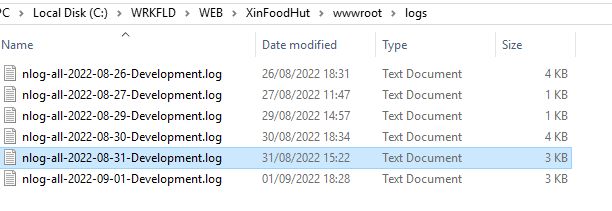
Questo file fornisce le indicazioni su come comporre il file, dove metterlo come mantenerlo… Come detto non mi dilungo troppo ma vi pongo l’accento su un paio di punti:
Questa riga sopra la utilizzo per definire come cartella dove salvare i files una cartella della www root, comoda se siete in una farm dove non avete controllo completo del file system. Per le Web API invece io uso questa dato che non esiste una wwwroot:
Questa parte invece definisce tutte le proprità del file di log: da cosa deve contenere ed in che formato, alla dimensione massima, al nome, alla rotation… Insomma tutto quello che serve per meglio definire come loggare. Non dimenticate di flaggare il Copy del file nell’output.
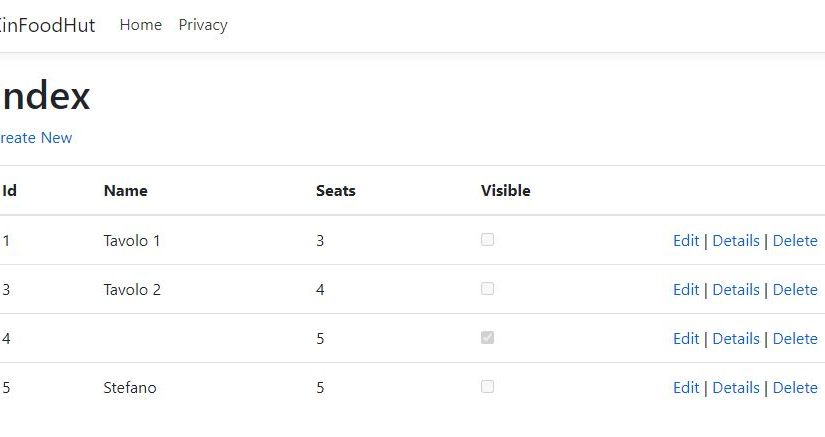
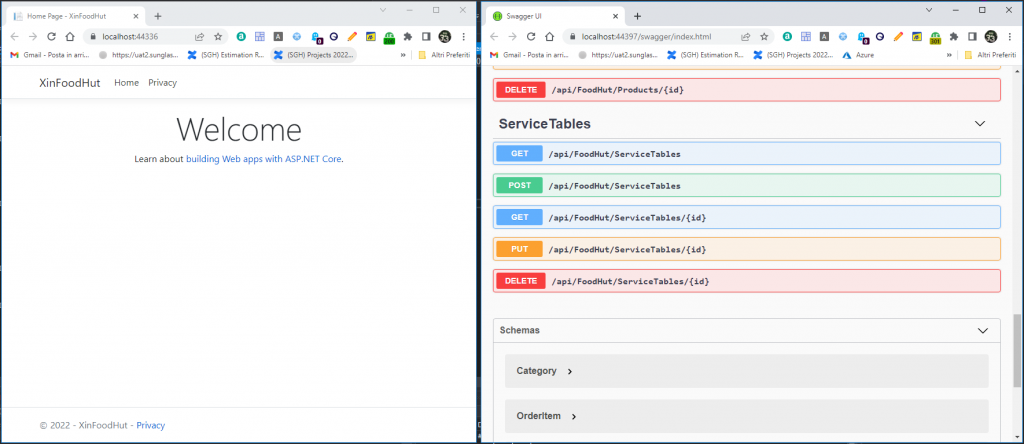
Come ricorderete in uno dei miei post precedenti [1] ci eravamo divertiti a creare una Web API con Swagger UI per fornire delle classiche funzionalità CRUD ad un fantomatico database di Fumetti. Ovviamente quella modalità si può applicare a mille oggetti differenti ma, è ora è venuto il momento di consumare l’API in una vera applicazione MVC e vedere come orchestrare il tutto. Per questo esempio farò uso di un’altra API che esporrà un oggetto ServiceTable che, almeno nelle mie intenzioni dovrebbe indicare il tavolo di un locale. Questà entità è molto semplice:
ID: è l’identificativo univoco del tavolo (la PK sul DB)
Name: è il nome del tavolo, non è obbligatoria ma potrebbe essere utile a chi vuole dare dei nomi a tema… chessò Acqua, Terra, Mare, Fuoco…
Supponendo quindi di avere già questa API all’interno di un progetto chiamato XinCommonAPI dobbiamo creare la web app che consumerà questa API ed implementerà l’interfaccia grafica (la UI). Aggiungiamo dunque alla soluzione con il progetto contenente la WebAPI un nuovo Progetto
Add new Project
e scegliamo un ASP NET Core Web APP assicurandoci che utilizzi il paradigma MVC
Create MVC Project
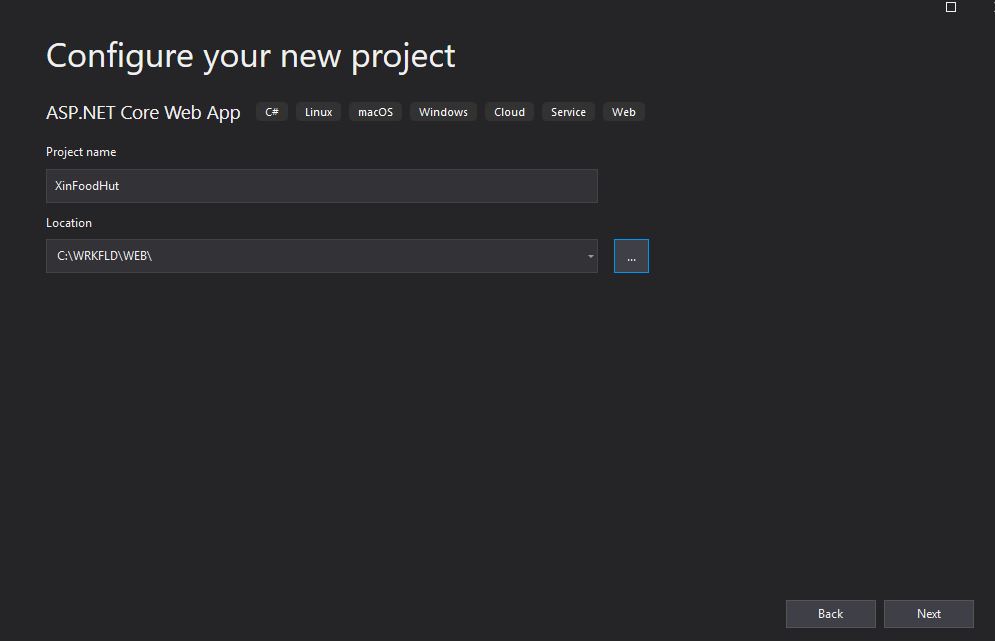
Scegliamo quindi come al solito la cartella dove posizionarlo
Choose location
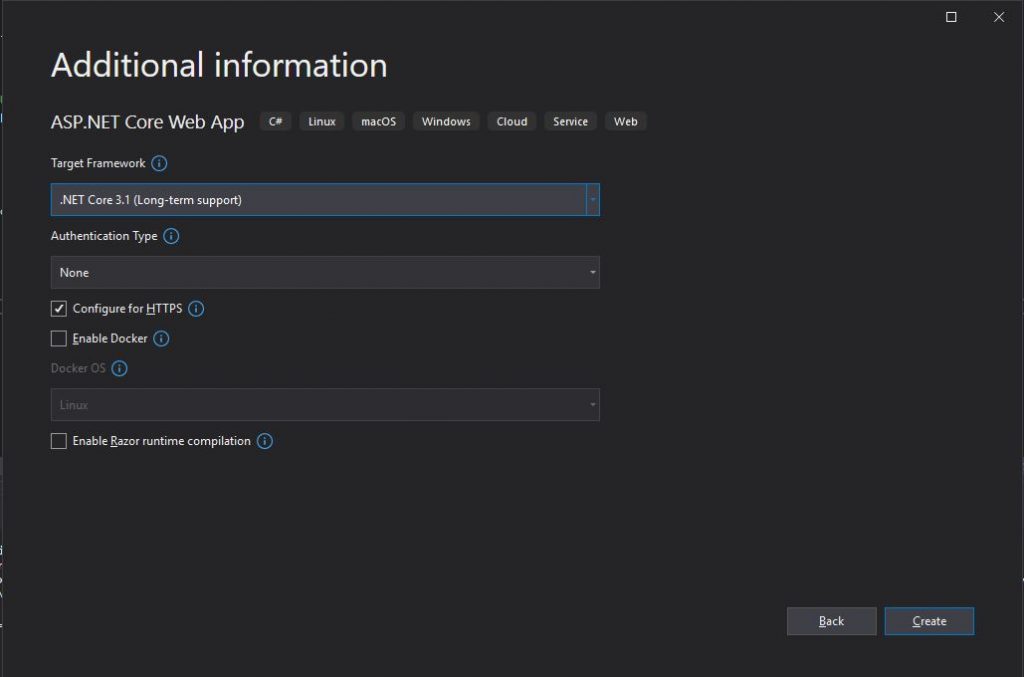
ed infine che tipo di framework vogliamo utilizzare
Framework and Authentication
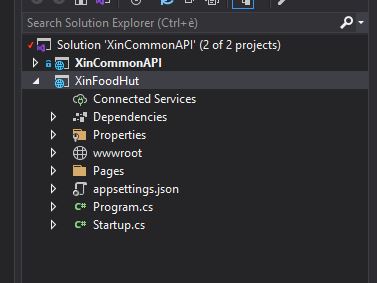
Alla fine di tutto questo avrò ottenuto il mio nuovo progetto ASP NET Core pronto all’uso
Web App Project
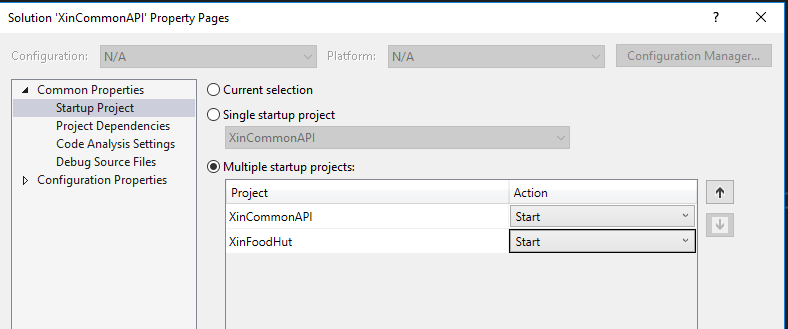
Naturalmente come sempre, prima di fare qualsivoglia modifica il suggerimento è di verificare che i progetti funzioni ed, in questo caso, che funzionino entrambi. Infatti la Web App deve consumare la Web API e quindi entrambi i progetti devono essere lanciati in DEBUG. Per fare questo dobbiamo aprire le proprietà della Solution creata ed impostare entrambi i progetti su Start
Starting Project
Ed in effetti lanciati i due progetti mi ritrovo quello che mi attendevo:
Le due web app
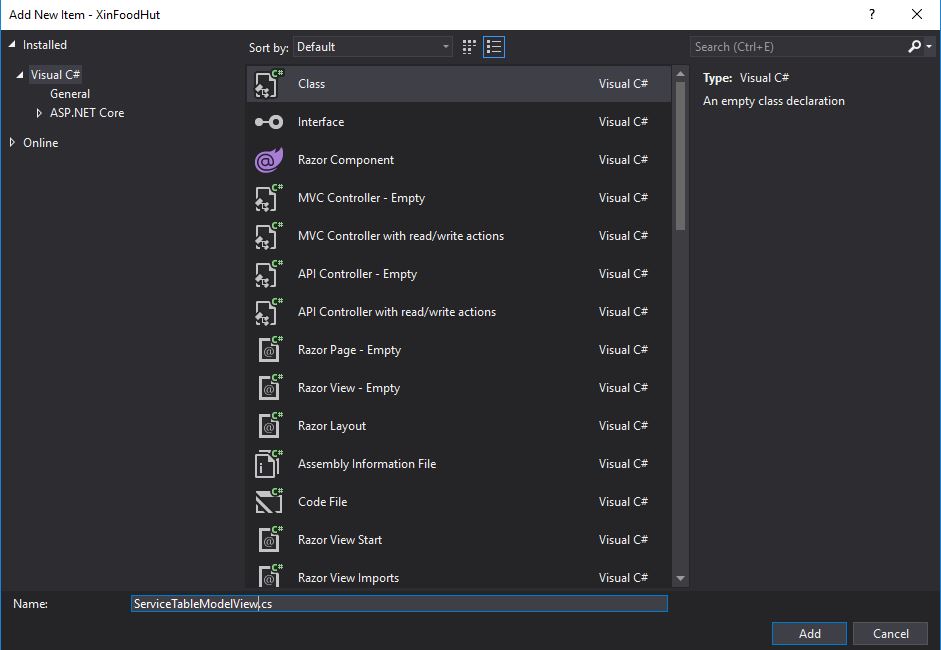
Ok, ora passiamo all’implementazione dell’operazioni CRUD in MVC. Anzitutto io consiglio di crearci una ModelView che rappresenti l’entità che andrà a rappresentare (il nostro ServiceTable) praticamente riproducendo lo stesso tipo di proprietà esposte nell’API.
Creare una classe ModelView che rappresenti l’entità TableService
E questo sarà il codice che immetteremo
public class ServiceTableViewModel
{
public int Id { get; set; }
public string Name { get; set; }
public int? Seats { get; set; }
public bool? Visible { get; set; }
}
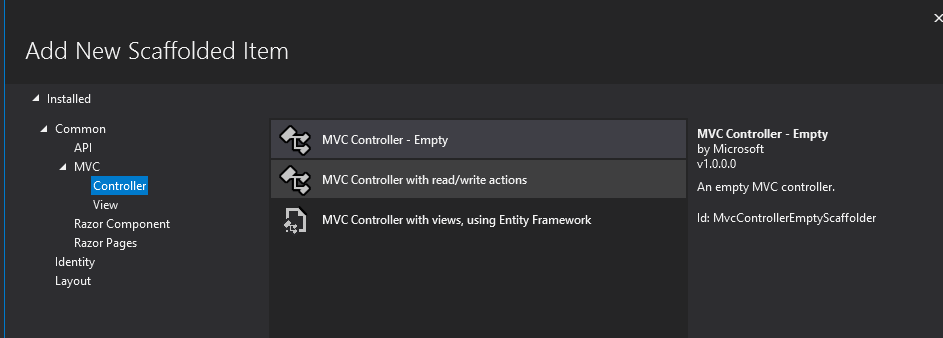
Ora passiamo a crearci un controller che vada a lavorare sulla Web API ServiceTable
Creare un Controller vuoto
Che chiameremo ServiceTableController.cs e che conterrà il seguente codice:
public class ServiceTableController : Controller
{
Uri baseAddress = new Uri("http://localhost:64853/api/FoodHut");
HttpClient client;
public ServiceTableController()
{
client = new HttpClient();
client.BaseAddress = baseAddress;
}
public IActionResult Index()
{
List<ServiceTableViewModel> modelList = new List<ServiceTableViewModel>();
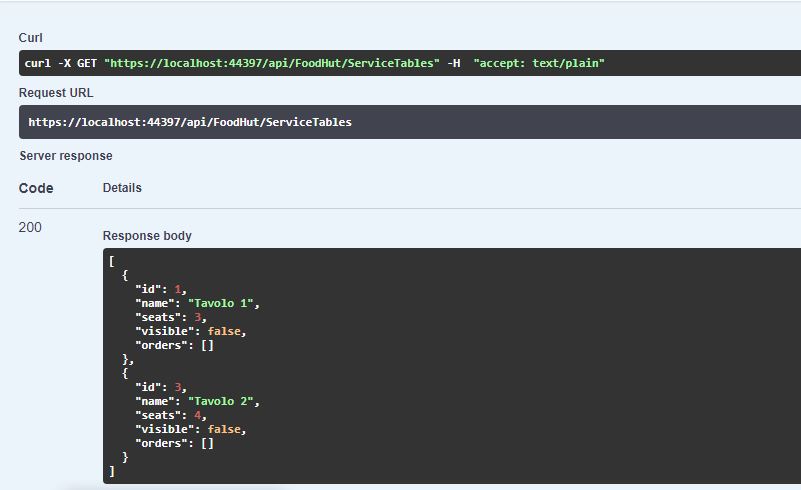
HttpResponseMessage response = client.GetAsync(client.BaseAddress + "/ServiceTables").Result;
if (response.IsSuccessStatusCode)
{
string data = response.Content.ReadAsStringAsync().Result;
modelList = JsonConvert.DeserializeObject<List<ServiceTableViewModel>>(data);
}
return View(modelList);
}
}
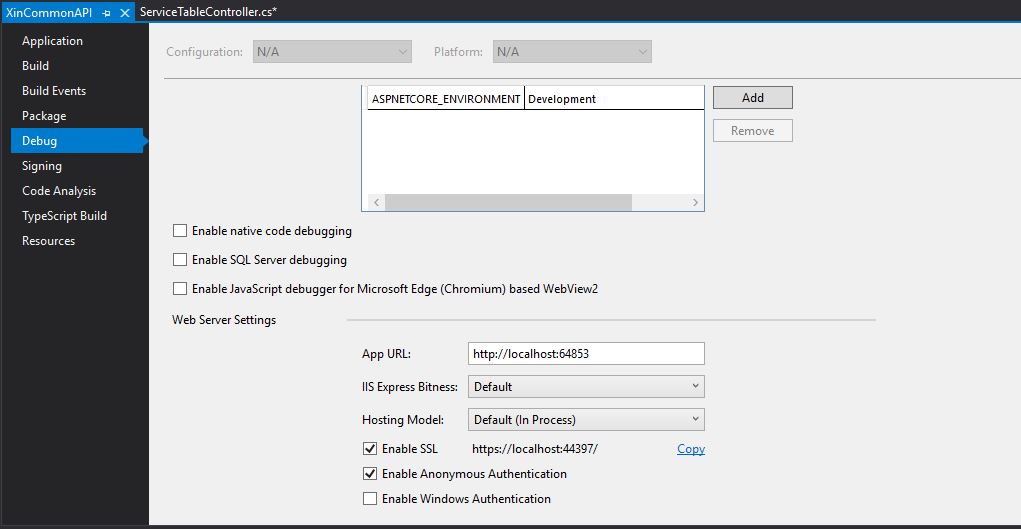
Andiamo a veder nel dettaglio che cosa abbiamo aggiunto nel codice: anzitutto l’URL dell’API ovvero l’endpoint che andremo ad interrogare dove stanno le API. Per l’ambiente di debug lo trovate tra le properties del progetto
URI base of API
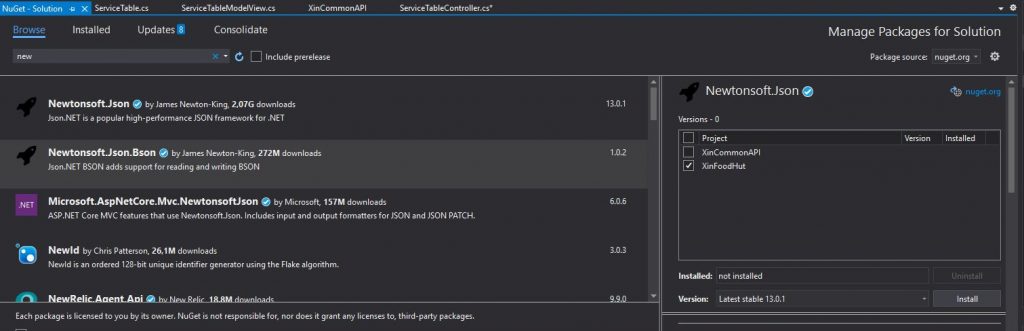
Questo Uri sarà quindi utilizzato per inizializzare l’oggetto HttpClient ed invocare la chiamata ottenendo la relativa response. Attenzione che essendo una chiamata Json il risultato va deserializzato facendo uso di un pacchetto Nuget specifico
Newtonsoft.Json library
Il codice in se per se è abbastanza autoesplicativo: si invoca l’API il risultato viene poi deserializzato e convertito nel ModelView relativo. Fate bene attenzione a che il ModelView riporti le properties con lo stesso identico name dell’API altrimenti il deserializzatore non sarà in grado di eseguire il mapping.
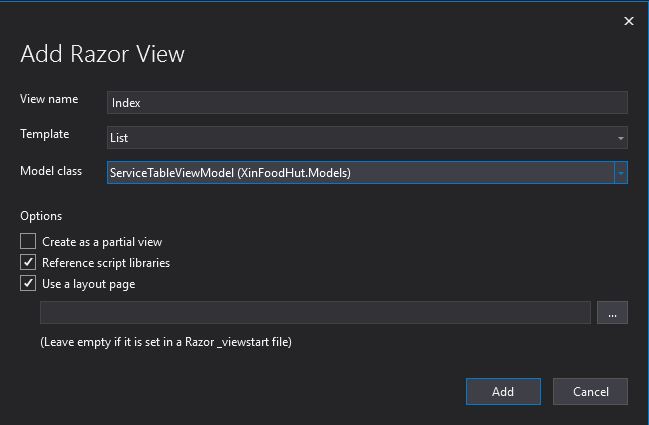
Fatto questo non resta che creare la view che visualizzi la lista dei ServiceTable e naturalmente come al solito la autogeneriamo posizionandoci sul metodo Index e quindi generiamo il tutto dal template List
List View
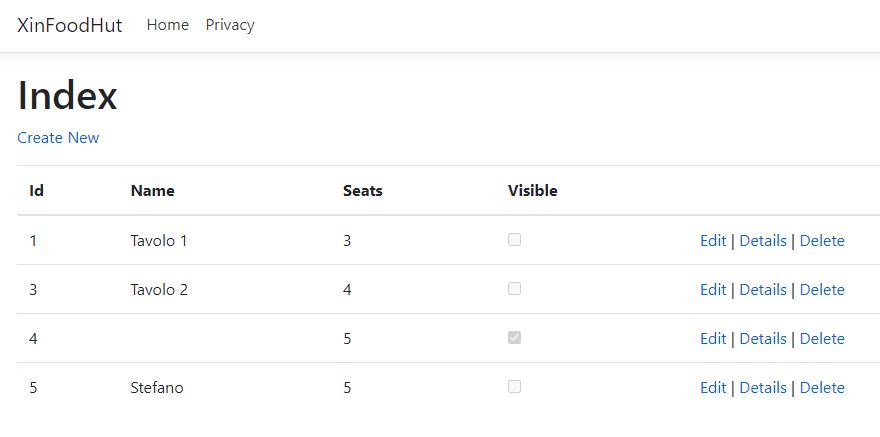
A questo punto è sufficiente lanciare in debug i due progetti ed ecco il risultato:
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Cookie strettamente necessari
I cookie strettamente necessari dovrebbero essere sempre attivati per poter salvare le tue preferenze per le impostazioni dei cookie.
Se disabiliti questo cookie, non saremo in grado di salvare le tue preferenze. Ciò significa che ogni volta che visiti questo sito web dovrai abilitare o disabilitare nuovamente i cookie.